概要
機械学習を使って3時間ごとの消費電力予測をグラフとして表示するデモ画面を作成しました
内容
今回は気象庁より2012~2014, 2016年の東京の 月, 曜日, 時刻, 気温, 天気 , 東京電力ホールディングスより2012~2014, 2016年の消費電力量を学習データとして使い消費電力予測を行いました。
処理の流れ
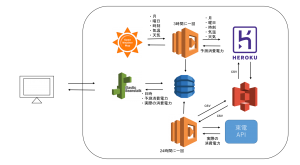
今回のシステムの概略図は上のようになっています。今回はHEROKU上に電力予測をするwebAPIを作成しました。
3時間に1度、フリーのAPIであるOpenWeatherMapより天気予報情報を取得しそこで得た情報から予測消費電力を天気情報とセットでdynamoDBに保存します。実測値に関しては東京電力電力供給状況APIを使用して取得し、同じようにdynamoDBに保存しています。
また、今回は精度向上のために実際に使用している間に収集したデータを学習データとして追加して1日に1回学習し直すことで日々少しずつ精度をあげる、ということをしています。この再学習に関しては学習時に使用したデータに新しいデータを追加したcsvファイルをS3に保存し、そのファイルをHEROKUから取得して学習し直し、モデルを更新しすることで実装しています。
学習方法
今回の学習方法として ランダムフォレスト というものを使用しています。ランダムフォレストとは、複数の 決定木 を使った手法です。
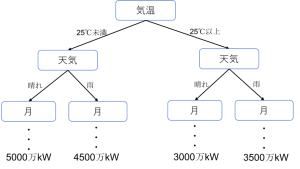
決定木とは、目的変数(今回は消費電力)に属する確率を複数の説明変数(今回は月, 曜日, 時刻, 気温, 天気)の組み合わせで算出する方法です。以下の図のように色んな条件の組み合わせを考えて出力が3000万kwになる確率、4000万kwになる確率…を学習していきます。ただこれが一つだけだと天気から考え始めた時、時刻から考え始めた時などを考慮できないためそれらを考慮した決定木も用意します。このように複数の決定木を集合させて学習させる方法をランダムフォレストといいます。
今回作成してみて…
機械学習をする上で大事なのは
- 目的がはっきりしていること
- 相関のある学習データが揃っていること
- 最適な学習法とパラメータを見極めること
- データの正規化を正しく行うこと
だと感じました。
本記事はQiitaにも記載していますのでよろしければぜひご覧ください。




