OpenCVって?
OpenCVは画像処理で有名なオープンソースのライブラリです。20年以上前から開発されているライブラリなので本当に色々なことができます。
例えば画像の回転やリサイズといった基本的な処理はもちろんですがエッジやコーナの検出といった古典的な特徴点計算や主成分分析などの統計的手法を用いた画像処理も扱うことができます。

さらに近年注目を集めている機械学習やAIモデル(ディープラーニング)も扱うことができ、日を追うごとに進化し続けています。そこで今回はAIモデルに着目して最新のOpenCVではどんなことができるのか調査してみました。
※ 調査対象は2021年12月リリースのバージョン4.5.5時点でPython実装されているものに限定しています。
OpenCVでAIモデルを使う
OpenCVで「データセットを使ってモデル学習!」といったことは残念ながらできないのですが、既に作成されたAIモデルを使って推論することは可能です。現時点でサポートされているフレームワークはPyTorchやTensorFlow, Darknet, ONNXなどを含めた合計6つで、これらのフレームワークで作成されたモデルファイルを読み込みことで推論することができます。
さっそく物体検出モデルYOLOv4をOpenCV上で動かしてみました。

犬と猫が四角い枠で囲まれています。物体検出ではこのように検出された物体を四角い枠で囲います。この四角い枠をバウンディングボックス(BBox)と呼びBBoxの上に書かれている数字が信頼度を表す数値(スコア)です。このスコアが1に近いほど推論結果の信頼度が高いことになります。
サンプルコード
事前準備として物体検出したい画像(今回はdog_and_cat.jpg)とモデルの設定ファイルyolov4.cfg, yolov4.weightsが必要です。なお、設定ファイルはこちらからダウンロードさせていただきました。
※ 用意する設定ファイルはフレームワーク毎に異なります。詳しくはリファレンスを参照ください。
import cv2
# 物体検出したい画像の読み込み
img = cv2.imread('./dog_and_cat.jpg')
# モデルの読み込み(Darknet)
net = cv2.dnn.readNet('./yolov4.cfg', './yolov4.weights')
# net = cv2.dnn.readNetFromDarknet('./yolov4.cfg', 'yolov4.weights')
model = cv2.dnn_DetectionModel(net)
model.setInputParams(scale=1 / 255, size=(416, 416), swapRB=True)
# 物体検出
detect_result = model.detect(img, confThreshold=0.7, nmsThreshold=0.4)
print(detect_result)
> [(array([15, 16], dtype=int32), array([0.76033837, 0.87054247], dtype=float32), array([[ 0, 219, 291, 260],[259, 156, 374, 259]], dtype=int32))※ 検出結果を画像に反映させる部分は省略しています。
サンプルコードの解説
# 物体検出したい画像の読み込み
img = cv2.imread('./dog_and_cat.jpg')
# モデルの読み込み(Darknet)
net = cv2.dnn.readNetFromDarknet('./yolov4.cfg', 'yolov4.weights')
# net = cv2.dnn.readNet('./yolov4.cfg', './yolov4.weights')
model = cv2.dnn_DetectionModel(net)
model.setInputParams(scale=1 / 255, size=(416, 416), swapRB=True)まず最初に今回物体検出したい画像と使用するモデルを読み込みます。今回Darknetを使用しているのでモデルの読み込みをreadNetFromDarknet()としていますがコメントアウトしているreadNet()でも同じように動作します。
次に読み込んだモデルの入力画像に必要な処理をセットしています。これを記述することで画像のスケール調整やリサイズ、色空間の反転処理といった入力画像に必要な前処理をOpenCV側でやってくれます。YOLOシリーズの他にもSSD(Single Shot Multibox Detector), Faster R-CNNといった物体検出モデルにも対応しているようです。
# 物体検出
detect_result = model.detect(img, confThreshold=0.7, nmsThreshold=0.4)物体検出はmodel.detect()で行われます。各種パラメータについて確認します。
confThresholdではスコアの閾値を設定します。この値を大きくすることでより信頼性の高いものだけ物体検出することになります。一方nmsThresholdではIoU(Intersection over Union)と呼ばれる値の閾値を設定しています。この値を大きくすることでBBoxの重なりを許容することになり、物体どうしが近くても正しく検出できるようになるのですが、あまりに大きくしすぎると同じ検出結果が排除されずダブりが生じます。例えばnmsThreshold=0.99と設定した場合、次のようにBBoxが重複した結果になります。

print(detect_result)
> [(array([15, 16], dtype=int32), array([0.76033837, 0.87054247], dtype=float32), array([[ 0, 219, 291, 260],[259, 156, 374, 259]], dtype=int32))最後に検出結果ですが左から検出した物体のリスト番号、スコア、BBoxの座標情報となっています。
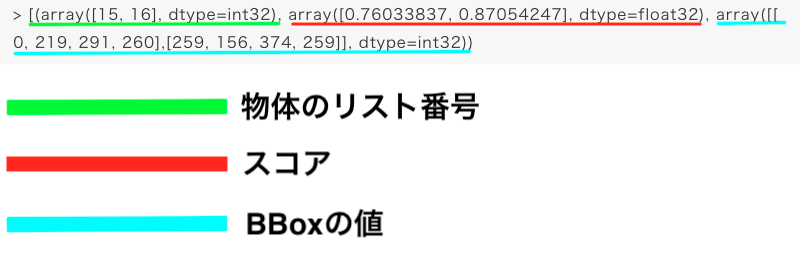
リスト番号というのは検出された物体がcoco.namesに記載されているリストの何番目のものなのかを表しています。Pythonの仕様上番号が1つ後ろにずれることに注意してください。例えば検出した結果の番号が15であればcoco.namesリストの16番目catを、16であればリストの17番目dogを指しています。
OpenCVの推論時間
OpenCV上でAIモデル推論できることはわかりましたが、スコアや推論時間はどうなっているのか気になったので調べてみました。今回はTensorFlowとONNXの2つのフレームワークでスコアや推論時間を計測します。調査はGoogle ColaboratoryのCPU環境Intel(R) Xeon(R) CPU @ 2.20GHzで実施しました。
OpenCV vs. TensorFlow
ImageNetで学習済みのDenseNet121モデルを使用して300回の推論時間の平均を計算しました。推論には次の画像を使用しました。

| フレームワーク | 推論結果 | スコア | 平均推論時間(sec) |
|---|---|---|---|
| OpenCV | 681(notebook / notebook computer) | 0.564565 | 0.188474 |
| TensorFlow | 681(notebook / notebook computer) | 0.564565 | 0.219263 |
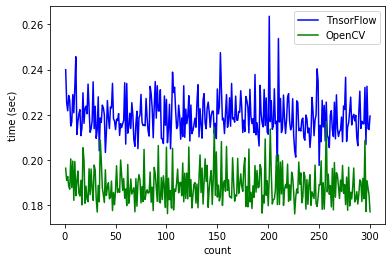
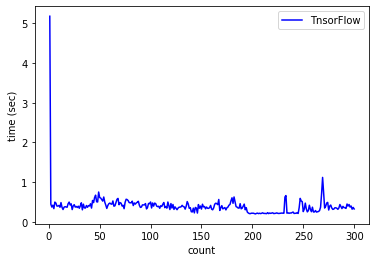
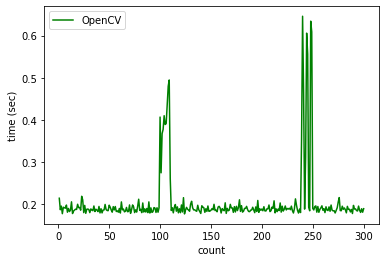
スコアは同じですが推論時間はOpenCVの方がはやいですね!!今回は計測から外しましたが、序盤の推論時間についてはTensorFlowの方が時間がかかる傾向にありました。一方でOpenCVは推論時間が不安定になる傾向がありました。
| フレームワーク | 1回目の推論時間(sec) |
|---|---|
| OpenCV | 0.429673 |
| TensorFlow | 5.207420 |
OpenCV vs. ONNX
次にONNXの計測ですがこちらは独自に作成した物体検出モデルを使用します。このモデルはPyTorchで上で学習したYOLOXモデルをONNXに変換したものです。YOLOXモデルの作成についてはこちらのブログで紹介していますので興味がある方は併せてご覧ください。こちらもGoogle ColaboratoryのCPU環境Intel(R) Xeon(R) CPU @ 2.20GHzで実施しました。また、推論に使用した画像と推論結果はこちらです。

| フレームワーク | 平均推論時間(sec) |
|---|---|
| OpenCV | 0.080006 |
| ONNX | 0.021513 |
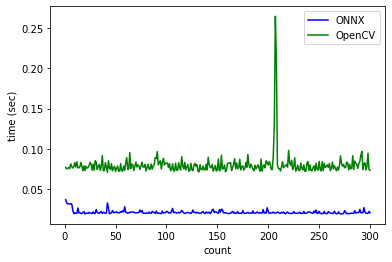
こちらはONNX Runtimeの圧勝ですね。OpenCVでONNXを使うと推論時間がやや遅くなる傾向があるのかもしれません。
まとめ
今回はOpenCV上で学習済みモデルやYOLOXで作成した独自モデルを動かしてみました。CPU環境下での検証ではOpenCVの方が推論時間が短くなるケースがあるということがわかりました。エッジデバイスのような使用ライブラリやリソースに制限があるような状況であってもOpenCVを使うことでAIモデルが利用できる可能性があることがわかりました。




