今回は2022 年4 月 21 日(米国時間)に一般公開(GA)されたAmazon SageMaker Serverless Inferenceを実際に触って利用方法を考えてみました。
SageMaker Serverless Inferenceとは
従来のSageMakerでは何が問題だったのか
これまでのSageMakerで使用できたリアルタイムエンドポイントでは推論サーバーを最低インスタンス(ml.c4.large)にて24時間常に起動した状態で運用した場合でも、月額約1万5千円ほどかかります。
プロダクションシステムで利用する際は機械学習による推論が主要な機能でも無い限り、利用料と金額が合わないことが多く、これまで導入を諦める場面が多くありました。
SageMaker Serverless Inferenceのメリット
そこで、SageMaker Serverless Inferenceの出番です。
SageMaker Serverless Inferenceは従量課金のサービスのため、推論を実行した時間にのみ料金が発生します。従来のようにインスタンスを常時起動させ続ける必要がないため、非常にコストを低く抑えることが可能です。従量課金という料金体系のため、より簡単に機械学習の推論をシステムへ導入することが可能になりました。
SageMaker Serverless Inferenceは「Amazon SageMaker版のAWS Lambda」のようなイメージで考えると理解しやすいかもしれません。推論開始時に実行環境が作成され、実行終了後に一定期間呼び出しがないと、実行環境は削除されます。
AWS Lambdaを用いて機械学習フレームワークを実行する際の課題点
SageMaker版のLambdaということはそもそもLambda上で機械学習フレームワークを実行すれば良いのでは?と考えられる方もいらっしゃるでしょう。
しかしLambdaを利用する場合、以下の制限が問題になります。
- デプロイパッケージのサイズ制限
- Lambda用の機械学習フレームワークの準備
まず、Lambdaだとデプロイパッケージのサイズ制限で機械学習フレームワークが乗らない場合があります。解凍後の合計データサイズが250MB以内に収まっている必要があるので、データサイズが大きい機械学習フレームワークをLambdaで実行する場合、データサイズが問題となることがありました。
また、そもそもLambdaへ乗せる機械学習フレームワーク自体を準備する必要があります。特に機械学習フレームワークはビルドが必要な場合が多く、ビルドする環境とLambddaの環境が異なると実行時にエラーが発生する、ということも起こる可能性があります。そのため、Lambdaと同じ環境を準備して、その環境でLambda用の機械学習フレームをビルドする、などの事前準備が必要です。
SageMaker Serverless Inferenceを利用する場合、上記で挙げた課題を解決してくれます。
Sage Maker Serverlessの制限について
先述した通りServerless Inferenceはコスト面で非常に優れたサービスですが、注意すべき制限事項が複数存在します。
まず、Serverless化に伴って生じるコールドスタートの問題です。実行環境を準備する時間はモデルのサイズや通信環境によって変動します。Amazon CloudWatchのメトリクスModelSetupTimeで環境設定までの時間を確認したところ、300MBほどのサイズのモデルではコールドスタートによる遅延は約28秒ほど発生していました。
また、従来のリアルタイムエンドポイントでは対応していることが、Serverlessでは対応していない項目が複数あります。
例えば、GPUの利用やマルチモデルエンドポイント、KMSキーの利用、VPCの構成などです。
他にも、モデルサイズはメモリサイズ以下である必要があることや、AWS Signature Version 4の認証情報を持たせたAWS CLI、InvokeEndpoint API経由でないとエンドポイントの呼び出しができないなど制限はまだ多いです。
私も最初推論用のAPIエンドポイントがパブリック公開されていると勘違いしていて、呼び出せなくて悩んでいました。
詳しくは公式のデベロッパーガイドをご確認ください。
実際にSageMaker Serverless Inference使ってみた
文章での説明はここまでにして、実際に触ってみた結果について記載します。
GAに伴ってSageMaker Python SDKでのデプロイもサポートされたので今回はそちらを使用してデプロイしてみました。
GA時には他にもエンドポイントあたりの最大同時呼び出し数の上限が 200 (プレビュー時は 50) に引き上げられ、より大規模なワークロードにも対応できるようになっています。
デプロイ方法の違い
モデル作成まではざっくり飛ばしてリアルタイムエンドポイントとの違いだけを説明します。
エンドポイント作成に必要なコードは以下のようになっており、SageMaker Studio上のノートブックインスタンスで実行しています。
MXNet Modelのクラスを作成した後、
from sagemaker.mxnet import MXNetModel
import sagemaker
role = sagemaker.get_execution_role()
# create MXNet Model Class
model = MXNetModel(
model_data = YOUR_MODEL,
role = role,
entry_point = "inference.py",
py_version = "py3",
framework_version = "1.6.0",
)リアルタイムエンドポイントでは以下のようにしてエンドポイントを生成していました。
realtime_predictor = model.deploy(initial_instance_count = 1, instance_type = 'ml.m4.xlarge')サーバーレスエンドポイントでは、メモリサイズと最大同時実行数のみを設定し、エンドポイントを生成します。
from sagemaker.serverless import ServerlessInferenceConfig
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb = 2048,
max_concurrency = 5
)
serverless_predictor = model.deploy(serverless_inference_config = serverless_config)このように引数を変更するだけでサーバーレスエンドポイントへ変更することができます。
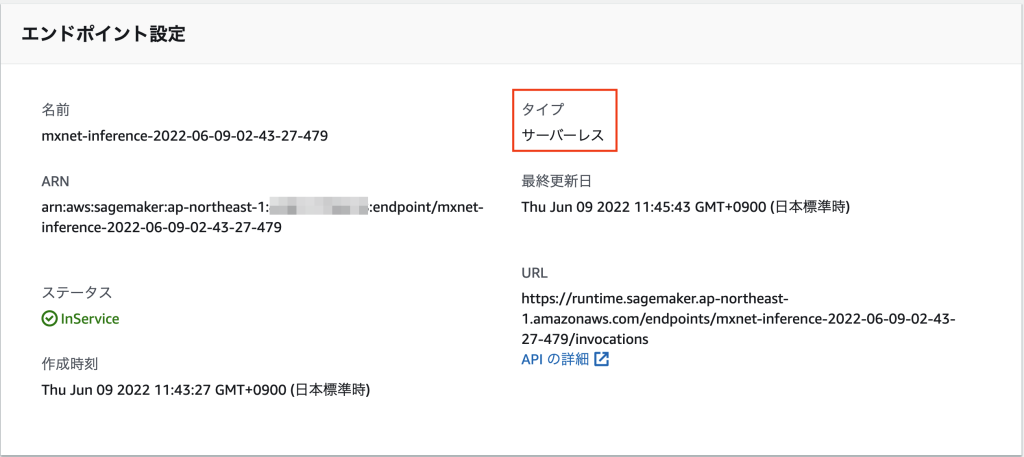
動作確認
今回作成したサーバーレスエンドポイントへアクセスし、動作確認を行いました。
その際に使用したコードは以下のものです。
import boto3
import json
img_jpg = "photo.jpg"
def query_endpoint(input_img):
endpoint_name = 'mxnet-inference-2022-06-09-02-43-27-479'
client = boto3.client('runtime.sagemaker')
response = client.invoke_endpoint(
EndpointName = endpoint_name,
ContentType = 'application/x-image',
Body = input_img,
Accept = 'application/json;verbose;n_predictions=3'
)
model_predictions = json.loads(response['Body'].read())
print(model_predictions)
return model_predictions
def parse_response(model_predictions):
normalized_boxes, classes, scores, labels = model_predictions['normalized_boxes'],
model_predictions['classes'], model_predictions['scores'], model_predictions['labels']
class_names = [labels[int(idx)] for idx in classes]
return normalized_boxes, class_names, scores
with open(img_jpg, 'rb') as file: input_img = file.read()
best_results_per_input = parse_response(query_endpoint(input_img))


boto3経由でアクセスして推論結果を取得することができました。
ユースケースについて
先述した通り、コールドスタートに28秒程度かかる可能性があるので、APIで利用する場合はAPI Gatewayの29秒制限に頻繁に抵触してしまうことが想定されます。
コールドスタートへの対策として、定期的にリクエストを空撃ちすることによって実行環境の削除を防止し、コールドスタートの発生を防ぐことができます(いわゆる暖気処理)。
しかし、コールドスタートを完全になくすためには常に最大同時実行数分の暖気処理をし続ける必要があり、この方法は一般的なユースケースにおいて現実的ではないと感じたので、別の方法も考えてみました。
例えば、画像を送ると画像に写っている人の名前を返す、というアプリケーションを作ることを想定した場合に以下のようなアーキテクチャが考えられます。
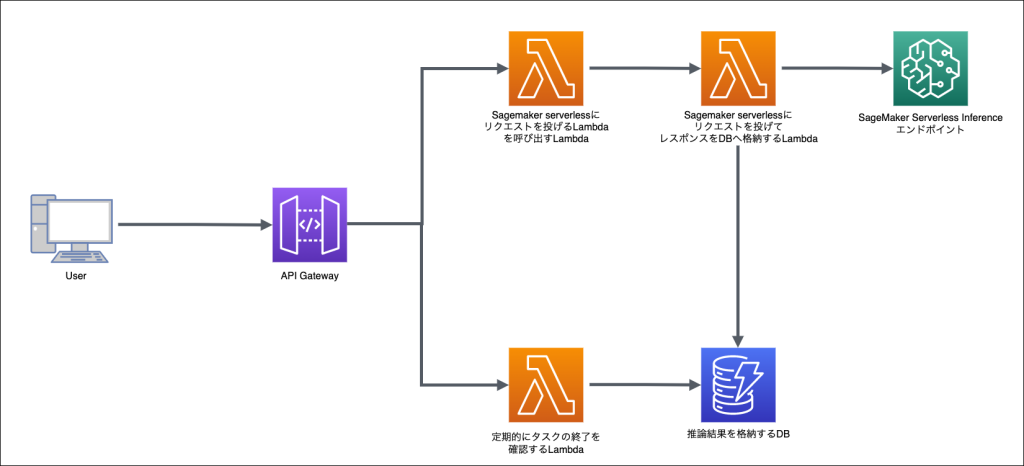
APIで呼び出しの起動のみ行い、その後テーブルに推論結果が書き込まれたかどうかを定期的にチェックするという方法です。
流れとしては、「画像送信」ボタンを押してAPIを呼び出す、LambdaがSageMaker Serverlessにリクエストを投げるLambdaを起動する、起動されたLambdaがサーバーレスエンドポイントへリクエストを送信し、そのレスポンスをDBへ格納、API呼び出し後別途画面側から定期実行されているLambdaがDBの更新を確認し画面へレスポンスを返す、レスポンスをもとに画像に名前をプロットして画面に表示、という処理内容です。
この方法であればAPI Gatewayの制限にかかることなく画面側に推論結果を渡すことができます。
まとめ
今回はGAされたAmazon SageMaker Serverless Inferenceを実際に触ってみました。まだまだ制限は多いもののSageMaker導入のハードルをグッと下げてくれるようなサービスだということがわかりました。条件に当てはまる場合リアルタイムエンドポイントよりもかなりコストダウンすることができます。また今後リアルタイムエンドポイントと同様の機能がサポートされていくと、より一層活用できる場面が広がっていくことが予想されます。
JAWS UG 京都にて登壇決定!
2022年8月7日(日)、「本気のAI」をテーマに京都、及びオンライン配信でJAWS UG京都を開催いたします。
当記事を書いたIoT.kyoto 若手メンバーも「これまでのSageMakerから脱却!!~サーバーレスと自動化を添えて~」のタイトルで登壇いたします。
詳細や参加申込みについてはお知らせ記事をご覧ください。




