概要
異常検知を教師なし学習で実現するモデルPatchCoreについての記事です。異常検知やPatchCoreの簡単な説明と実際に使ってみた様子をお伝えします。このモデルを使ったデモ作成の様子についてはこちらの「Vieureka(AIカメラ)で異常検知デモを作成しました!」をご参照ください。
そもそも異常検知とは
異常検知(Anomaly detection)とは、膨大なデータの中から他とは違う状態のデータを検出する技術です。具体例として次のようなものが挙げられます。
| 概要 | 具体例 | 対象データ |
|---|---|---|
| 侵入検知 | システムやネットワークで発生するイベントを監視し、侵入を検知 | ログデータ(時系列データ) |
| ビデオ監視 | 設置した防犯カメラから不審者などの侵入を検知 | 画像(時系列データ) |
| 製造不良品 | 製造業で生産される部品などの不良品を画像から検知 | 画像(非時系列データ) |
| スパムメール | スパムメール(チャット)や詐欺メール(チャット)を検知 | メール文(非時系列データ) |
このように異常検知で扱う分野は幅広いため、社会実装への期待が高い技術と言えます。
今回は製造業で行われている目視による外観検査を対象とした異常検知について調査したので以下ではそれにフォーカスを当てていきたいと思います。
異常検知で使用されるモデル
異常検知には専用の特別なモデルがあるわけではなく一般的な統計モデルや機械学習モデルが使われます。
統計モデル、機械学習モデルの違い
どちらもデータから何らかの付加価値を創造するという目的を持った数理モデルですが、統計モデルはデータの「説明」に、機械学習モデルはデータの「予測」に重きを置いているという点で違いがあります。ただし、技術や手順に大きな違いはないことが多く区別しないこともあります。
異常検知で使用されるモデルには教師あり学習のものがたくさんありますが、最近では教師なし学習が増えてきています。今回のように製造業などで発生する不良品を画像データから見つけるには教師なし学習の方が適切なことが多いでしょう。
工場などで生産している製品の大半は正常なもので不良品は全体の数%以下です。こうした場合に教師あり学習を実施するとなると不良品の学習画像データを準備することが大変になります。また、不良品の定義が明確でない場合はモデルの精度が下がってしまう可能性があります。
| 学習方法 | 判断基準 |
|---|---|
| 教師あり学習 | 不良品の不良パターンが明確で限られている。不良パターンの学習データが大量にある。 |
| 教師なし学習 | 不良品のデータがない。不良品の不良箇所が不明 |
教師なし異常検知モデルはその名の通り教師なしモデルなので正常な画像のみを用いてモデル作成します。そのため、教師あり学習と比較すると異常な画像の情報が圧倒的に不足します。この情報量の不足によってAIがうまく異常を見つけ出せないことが課題でした。
この課題を解決すべく作成されたモデルの一つがPatchCoreです。
異常検知モデルPatchCore
PatchCoreは画像データから異常検知を実現するモデルで、データセット「MVTecAD」でSOTA(State-of-the-Art)を達成しています。つまり、画像データから異常検知を実現する教師なし学習モデルのベンチマーク性能はトップクラスということです。
MVTecADとは
MVTec ADは、工業検査に特化した異常検出手法のベンチマーク用データセットである。このデータセットには、5000枚以上の高解像度画像が含まれており、15の異なるオブジェクトとテクスチャのカテゴリに分けられています。各カテゴリは、欠陥のないトレーニング画像セットと、様々な種類の欠陥がある画像と欠陥のない画像のテストセットで構成されています。

このモデルの特徴は何と言っても深層学習をしないことです。あらかじめImageNetで学習させた学習済みのResNetシリーズモデルを使用して画像データの特徴量抽出します。こういった手法は以前からありましたが、PatchCoreではさらに位置情報を保持したり、浅い層と深い層の出力は使わないようにしたりと異常検知タスクにマッチするような工夫が施されています。より詳しい説明は論文を参照ください。
実際に使ってみた
MVTecADのHazelnut(ヘーゼルナッツ)データセットを使って実際にモデルを試してみました。データセットはこちらからダウンロードできます。
ダウンロードしたデータセットの中身は次のような構成になっています。
.
├── ground_truth
│ ├── crack
│ ├── cut
│ ├── hole
│ └── print
│
├── license.txt
├── readme.txt
├── test
│ ├── crack
│ ├── cut
│ ├── good
│ ├── hole
│ └── print
└── train
└── good
異常データとしてcrack(割れ目), cut(切れ目), hole(穴), print(文字印刷)が用意されています。ground_truthはtestデータに対応していて異常箇所を白抜きにした画像が保存されています。
実際にPatchCoreを動かしてみました。
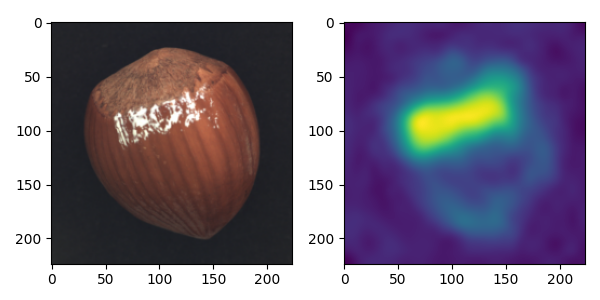
このようにヒートマップ図を作成してくれるのでモデルが異常と判断している箇所がわかります。モデルの妥当性を確認しやすいのはいいですね。なお、公開されているソースコードはtestディレクトリにある画像を一括で処理されることに注意です。
また、自前のデータセットも試してみました。付箋数十枚をデータセットとして学習させてシールを異常箇所と見立ててテストしてみました。
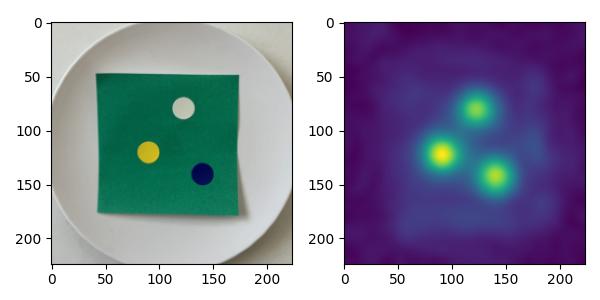
深層学習をしない教師なしモデルがSOTA(State-of-the-Art)を達成していることは驚きです。一方で、実際の外観検査に導入するには精度、実行環境という点で課題があるのも事実です。また、適切な条件下での教師あり学習モデルに比べると精度はまだまだ低いと言わざるを得ません。
最後に
PatchCoreにSelf-attentionを導入して精度向上を図っているモデルがでてきたりと、まだまだ発展途上のモデルなので引き続きウォッチしたいと思います。
参考文献
Towards Total Recall in Industrial Anomaly Detection
曽我部東馬(2021)『Pythonによる異常検知』.オーム社.




