はじめに
IoT.kyotoでは、その名の通りIoTを主軸としたサービスを提供しています。
先日、IoT.kyotoデータレイクおまかせパックの追加をお知らせいたしました。
本記事ではデータレイクについて、一見無関係に思われるIoTとどのような関わりがあるかご説明いたします。
IoTの基本的な構成・データレイクとの関係
まずIoTでは、センサー類がセンシングしたデータをクラウドへ送信することが基本の構成となります。
クラウドへ送信したデータの主な使い方は、導入事例等をご覧いただくとわかりやすいと思いますが、可視化の画面を作ることが多いです。

センシングデータをグラフ等を用いて可視化することで、現在のセンシング場所の状態がどうなっているのか遠隔監視を行ったり、クラウドへ届いたデータを分析し、閾値を超えたらアラートを送信するなど、リアルタイムでデータを活用をしています。
可視化画面が完成して運用が始まってから、保存しているデータに対して可視化のみではなく分析をしたいとご連絡いただくケースがあります。
詳しくはAWSのサービスの説明も交えて後述いたしますが、可視化画面に必要な構成のみだと分析には適していません。
また、センサー類からの送信頻度にもよりますが、システムの稼働時間が経過するにつれて、クラウドへ保存されるデータ量は膨大なものとなっているので考慮が必要となります。
そこで登場するのがデータレイクです。
データレイクとは
データレイクとはストレージの一種です。似たものとして、データウェアハウスというものがありますが、どちらも特徴としては膨大なデータを保存するという点です。
データレイクはストレージですが、データを保存すること自体が役割ではなく、保存したデータに対して、機械学習を行ったり、分析を行う基盤となることが主な役割となります。
データレイクでできること
データレイク(data lake)は、lakeを直訳すると、「湖」となることからもわかるように、大量のデータを保存することが得意です。
大きな特徴として、保存するデータの構造を決めておく必要がありません。
クラウドへ届いたデータをそのまま保存することが可能です。
そのため、IoTのシステムを導入する目的として、当初は可視化のみの予定でも、データレイクに保存しておけば、のちのち機械学習や、分析を行うことが容易となります。
データレイクはデータベースではないため、機械学習や分析を行う際にデータベース専門の知識は必要ありません。
また、可視化に必要なデータベースとは保存される場所が異なるため、データ抽出時に影響を与えることなく、任意のタイミングでデータを扱うことができます。
構造化されていないデータのため、データ抽出の難易度が高くなりがちですが、AWSではデータレイクに特化するサービスがあるため、比較的容易に利用可能です。
AWSでのデータレイク
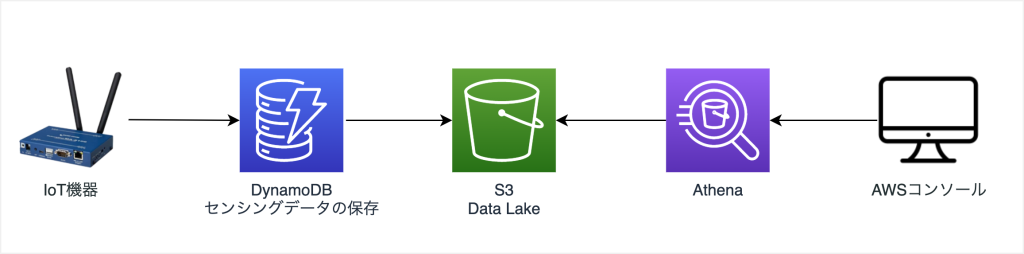
AWSでIoTシステムを構築する場合は、データの保存場所としてAmazon DynamoDBを使うことが一般的です。
DynamoDBの詳しい説明は省きますが、利用するメリットとして、データ構造の変更にも強く、保存容量に制限がなかったり、負荷に合わせたスケーリングが容易であったりと、IoTとの相性が非常に良いです。
デメリットとしては、一度に大量のデータを取得するのには向いていなかったり、検索の条件指定に制約があったり、大量のデータを保存すると安くはないコストが発生しますので、データレイクの保存としては不向きです。
そこで登場するのが、Amazon S3 + Amazon Athenaの組み合わせです。
Amazon S3はストレージサービスです。
非常に安価で堅牢なストレージですので、大量のデータの保存はS3の得意とするところですが、Amazon S3単体だと複雑なデータ抽出が苦手です。
その苦手な部分をサポートするのがAmazon Athenaです。Amazon Athenaを使うことでAmazon S3に保存されたデータをSQLなどでデータを高速に抽出できるようになります。
簡易的なアーキテクチャは以下となります。
まとめ
本記事ではIoTとデータレイクの親和性について記載いたしました。
データレイクってIoTと相性がいいんだなと思っていただければ幸いです。
IoT.kyotoではデータレイクのサービスも提供しています。
現在HPに掲載準備中です。以下は展示会で発表したパネルです。

ご興味ある方はぜひお問い合わせください。




