Amazon SageMaker Jumpstartとは?
機械学習をスピーディーかつ、簡単に始められるサービスです。
本来、機械学習を始めるには、データセットの準備、アルゴリズムの選択、モデルのトレーニング、精度の最適化、本番稼働環境へのデプロイ、パフォーマンスの経時的モニタリングといった、数々の障壁をクリアする必要があります。しかしAmazon SageMaker Jumpstart(以下、SageMaker Jumpstart)を用いると、数回クリックしただけで、すでに学習済みのモデルを備えたインスタンスをデプロイすることができます。
今回は機械学習初心者の私が、実際に推論インスタンスを立ち上げて、画像を推論し、さらにファインチューニングを用いて、新しい機械学習モデルを作成した経験を記していきます。
SageMaker Jumpstart でファインチューニングをしてみる
本記事では、用意されているオープンソースモデルの一つであるResnet 34をデプロイして、画像の推論を行います。
ResNet 34はすでに1000種類のクラス分類がされているモデルですが、詳細な花の分類ができるモデルではありません。
そこでResnet 34ですでに作成されたモデルを元にファインチューニングを行い、元のモデルではラベリングされていなかった花の画像の推論が、正しく行えるようになったか見ていきたいと思います。
ユーザープロファイルを作成する
Amazon SageMaker JumpStart は機械学習のための統合開発環境である Amazon SageMaker Studio(以下、SageMaker Studio)の中に、統合されているため、SageMaker Studioを起動します。
まずはじめに、SageMaker Studioを起動するためのユーザープロファイルを作成します。
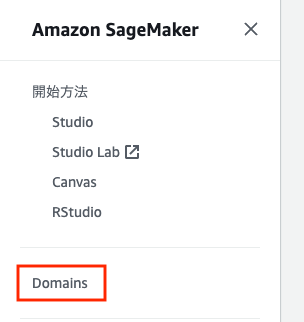
Amazon SageMakerのコンソールを表示してサイドバーにある「Domains」を選択します。
今回はデフォルトのドメインにユーザープロファイルを作成していきます。
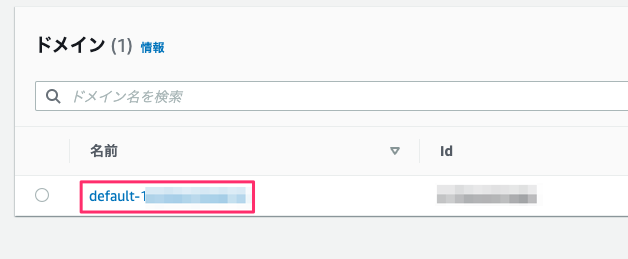
デフォルトのドメインの管理画面に遷移したら「ユーザーを追加」ボタンを選択してユーザーの作成をします。
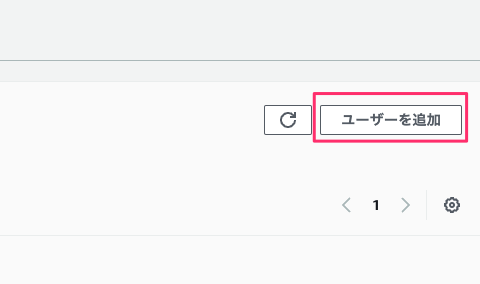
ユーザー名のみわかりやすいように変更して、あとは特に設定は変更せずにユーザー作成します。
以上でユーザーの作成は完了です。
※ SageMaker JumpStartを利用するためには、SageMaker Studioの設定で、SageMaker JumpStartを有効化しなければならないので、対象ドメインの[設定を編集]から有効化にチェックが入っている必要があります。
SageMaker Studioを起動する
作成したユーザーを使ってSageMaker Studioを起動します。
ドメインの画面に先程作成したユーザーが表示されているので、該当ユーザーの「起動」ボタンを選択した後に「Studio」を選択します。
これでSageMaker Studioの起動をすることができます。
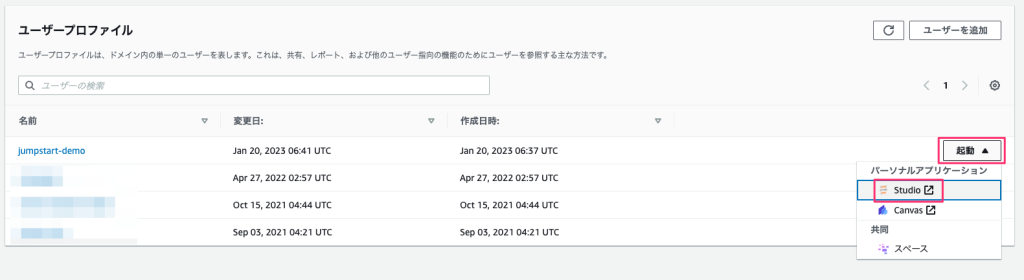
SageMaker Jumpstartの画面に移動
SageMaker Studioを起動すると、下記の画像のような画面に遷移しますので、赤枠の部分をクリックして SageMaker Jumpstartの画面を開きます。
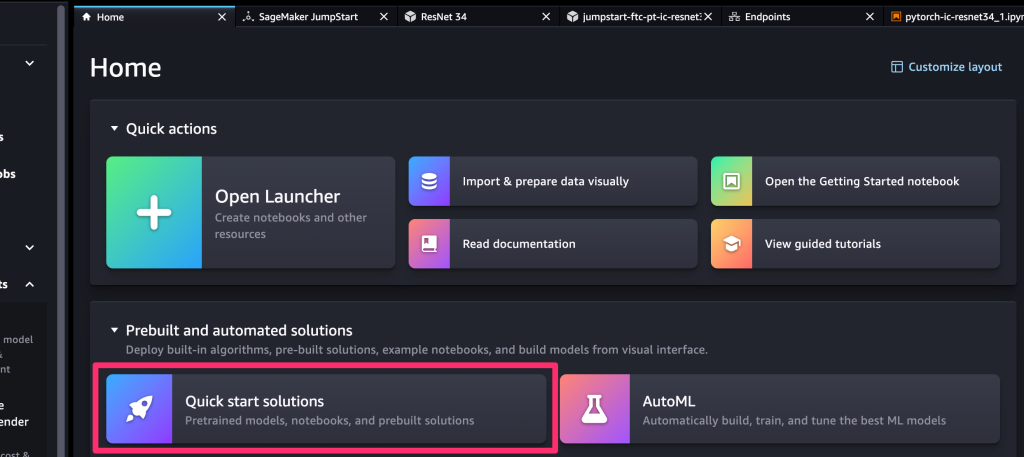
学習モデルを選択
150以上の事前トレーニング済みのオープンソースモデルが用意されています。
これまではAmazon SageMakerでオープンソースのモデルを利用するためには、推論エンドポイントを作成するためにソースコードを書く必要がありました。
SageMaker JumpStartでは、この書き換えの手間が必要なく、ワンクリックでオープンソースモデルのデプロイができます。
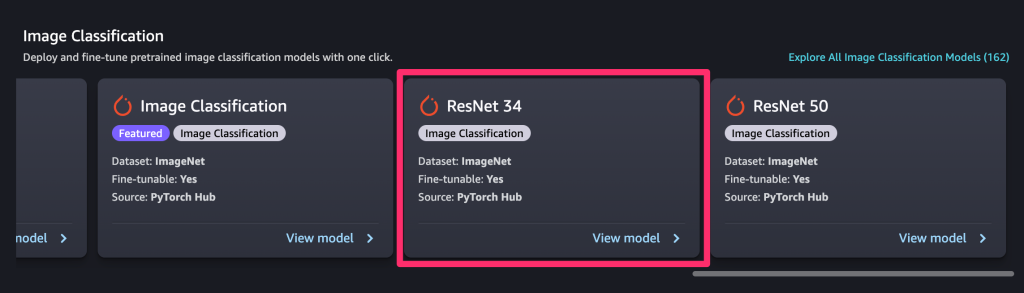
今回は[ResNet 34]というモデルを選択します。
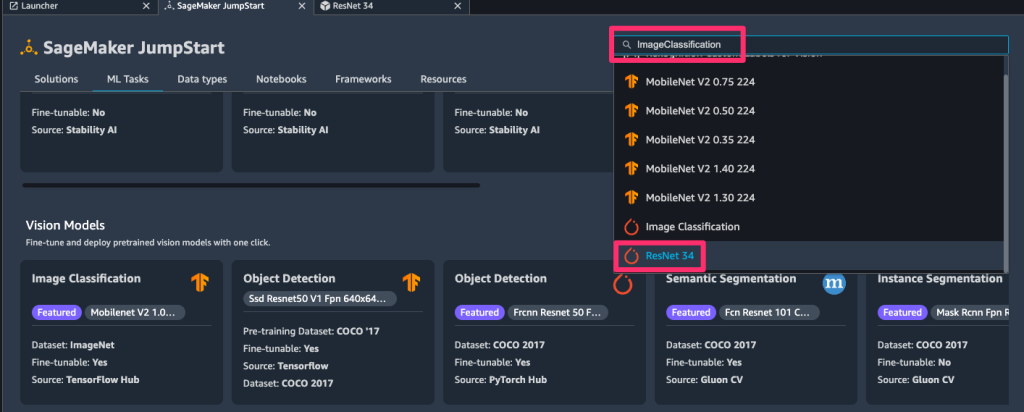
見つからない場合は「ImageClassification」で検索することで選択することもできます。
オープンソースモデル(ResNet 34)をデプロイする
一度、事前にトレーニングされたモデルをデプロイしてみます。
Deployment Configuretionのプルダウンをクリックすると、インスタンスタイプやエンドポイント名を指定できます。
今回はデフォルトのままデプロイします。
ステータスがIn Serviceになれば、デプロイ完了です。
サンプルノートブックを開く
デプロイした画面の[Open Notebook]をクリックすると、ノートブックが開きます。

コードの解説
import boto3
from IPython.core.display import HTML
region = boto3.Session().region_name
s3_bucket = f"jumpstart-cache-prod-{region}"
key_prefix = "inference-notebook-assets"
s3 = boto3.client("s3")
def download_from_s3(key_filenames):
for key_filename in key_filenames:
s3.download_file(s3_bucket, f"{key_prefix}/{key_filename}", key_filename)
cat_jpg, dog_jpg, ImageNetLabels = "cat.jpg", "dog.jpg", "ImageNetLabels.txt"
download_from_s3(key_filenames=[cat_jpg, dog_jpg, ImageNetLabels])1つ目のセルで、公開されているS3から、犬と猫のサンプル画像をSageMaker Studio内にダウンロードします。
images = {}
with open(cat_jpg, 'rb') as file: images[cat_jpg] = file.read()
with open(dog_jpg, 'rb') as file: images[dog_jpg] = file.read()2つ目のセルで、先ほどS3からSageMaker Studio内にダウンロードしたサンプル画像を読み込みます。
import json
def query_endpoint(img):
endpoint_name = 'jumpstart-dft-pt-ic-resnet34'
client = boto3.client('runtime.sagemaker')
response = client.invoke_endpoint(EndpointName=endpoint_name, ContentType='application/x-image', Body=img, Accept='application/json;verbose')
return response
def parse_prediction(query_response):
model_predictions = json.loads(query_response['Body'].read())
predicted_label = model_predictions['predicted_label']
labels = model_predictions['labels']
probabilities = model_predictions['probabilities']
return predicted_label, probabilities, labels
for filename, img in images.items():
query_response = query_endpoint(img)
predicted_label, probabilities, labels = parse_prediction(query_response)
display(HTML(f'<img src={filename} alt={filename} align="left" style="width: 250px;"/>'
f'<figcaption>Predicted Label is : {predicted_label}</figcaption>'))3つ目のセルで推論を行います。client.invoke_endpoint の引数の中に、先ほど立てたResNet 34の推論インスタンスのエンドポイントと、画像を渡してやるだけで、推論することができます。
試しに上から順に実行をしていきます。
※Shift + Enterで各セルのコードを実行することができます。
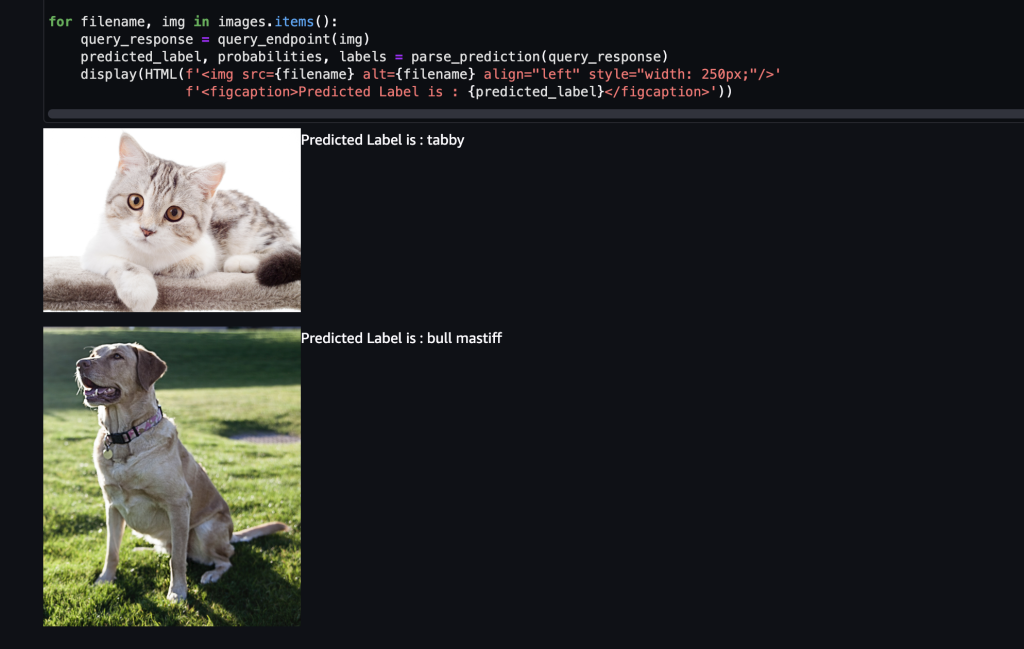
サンプルのコードだとこのような形で推論できます。
あまりに簡単に推論ができたので、唖然としてしまいました。
推論結果ですが犬も猫も、正しく推論されていますね。
ではこちらのモデルでラベリングされていない花の画像を読み込んで、推論をさせるとどうなるのか見てみたい思います。
ラベリングされていない画像を推論してみる
推論インスタンスに、ResNet 34にラベリングされていない花の画像を渡して、推論してみます。
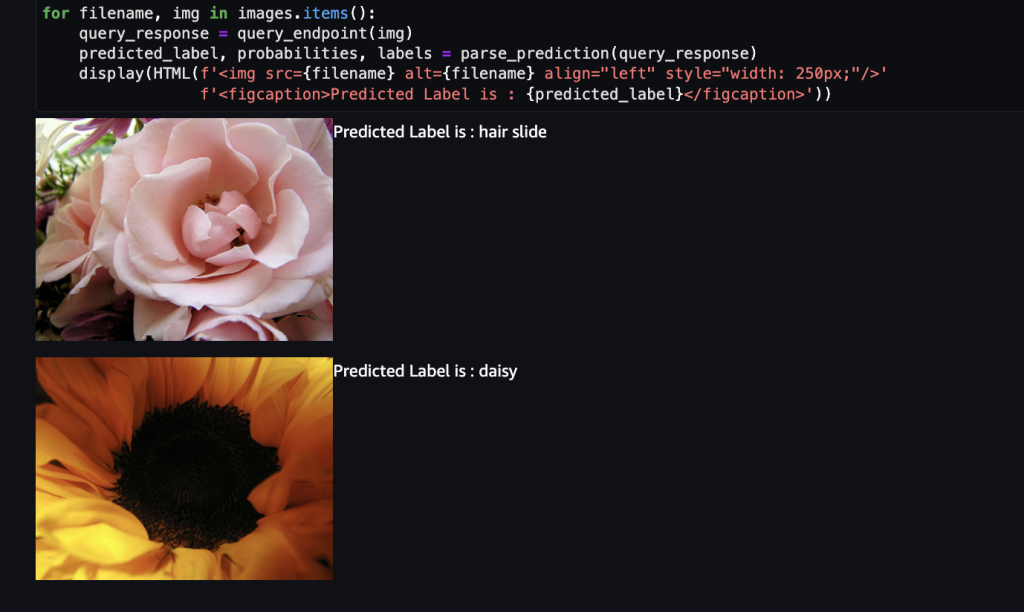
ひまわりの方はデイジーと推論されていて、惜しくもないのですが、バラの方はヘアスライド(髪留め)と認識されていて面白いですね。
ResNet 34では、これらの花はラベリングされておらず、正しく推論できないのは当たり前なので、これからファインチューニングをして、これらの花を分類できるモデルを新しく作成します。
ファインチューニングしてみる
補足:ファインチューニングと転移学習の違い
今回、SageMaker Jumpstartでは転移学習ができると思って利用したのですが、実際はファインチューニングという手法でした。
どちらも既存の学習モデルから、新しいモデルを作成するのですが、両者には違いがあるので補足します。
転移学習
転移学習は、学習済みのモデルのネットワークの重みを固定して、最終出力層に分類したいクラスを追加することで、新しいモデルを作成します。
ファインチューニング
ファインチューニングは、学習済みモデルの重みを初期値として、再度全体で学習することで、ネットワークの重みの微調整を行い、新しいモデルを作成します。
今回はファインチューニングを用いて、ResNet 34では行えなかった、花の分類をできるように新しいモデルを作成します。
S3にデータセットを保存する
ファインチューニングする方法はオープンソースモデル(今回だとResNet 34)をデプロイする画面の下部に書かれています。
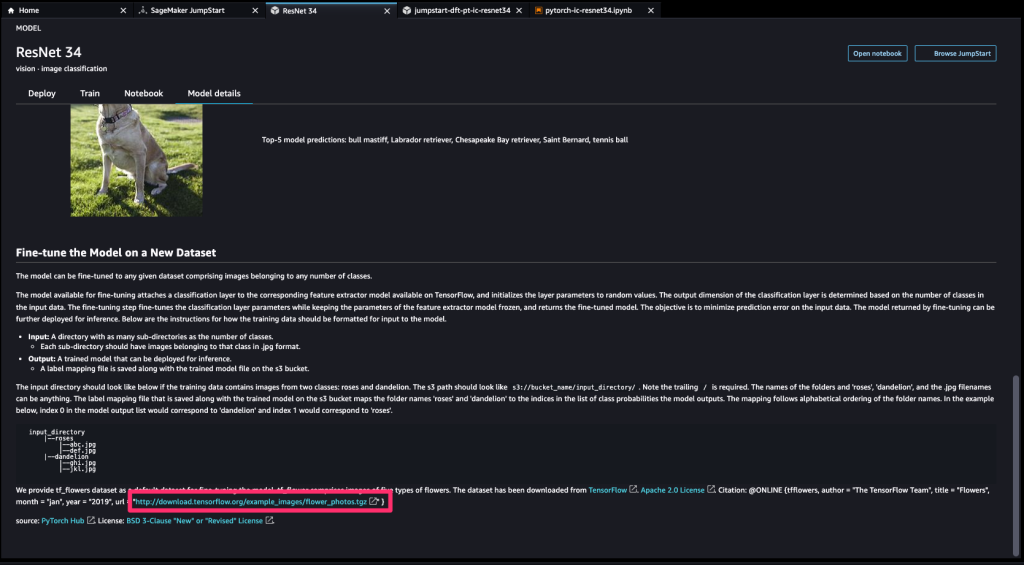
ラベリングしたい項目ごとにフォルダを作成し、その中に画像をひたすら入れていきます。
(rosesというフォルダの中に、バラの画像を入れていく)
今回は赤枠部分のリンクから、サンプルデータセットをダウンロードして、それを使用してファインチューニングを行います。
※ この際に何枚かの画像を推論用に省いておいてください。
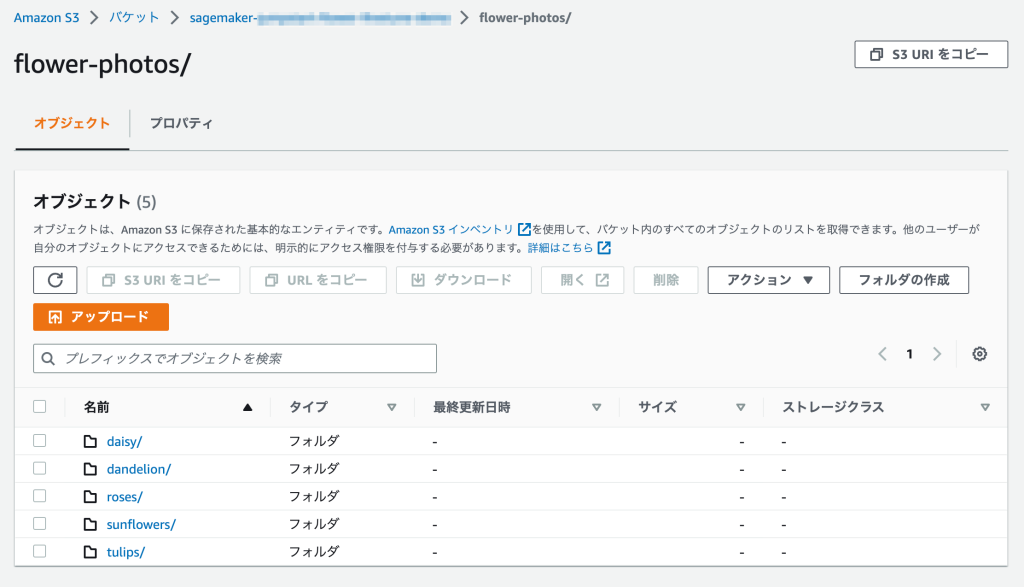
ダウンロードしてきたサンプルデータセットをS3にアップロードしました。
今回は5種類の花の識別ができるモデルを作成していきます。
トレーニングする
先ほどアップロードしたS3バケットのアドレスを指定して [Train] をクリックします。
これだけでファインチューニングができます。
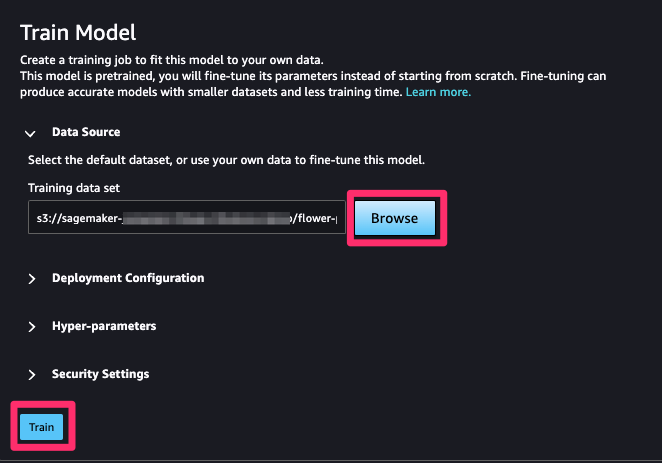
下記のようにトレーニングするインスタンスのタイプや、ハイパーパラメーターの設定も行うことができます。
今回はデフォルトの設定のままで行いました。
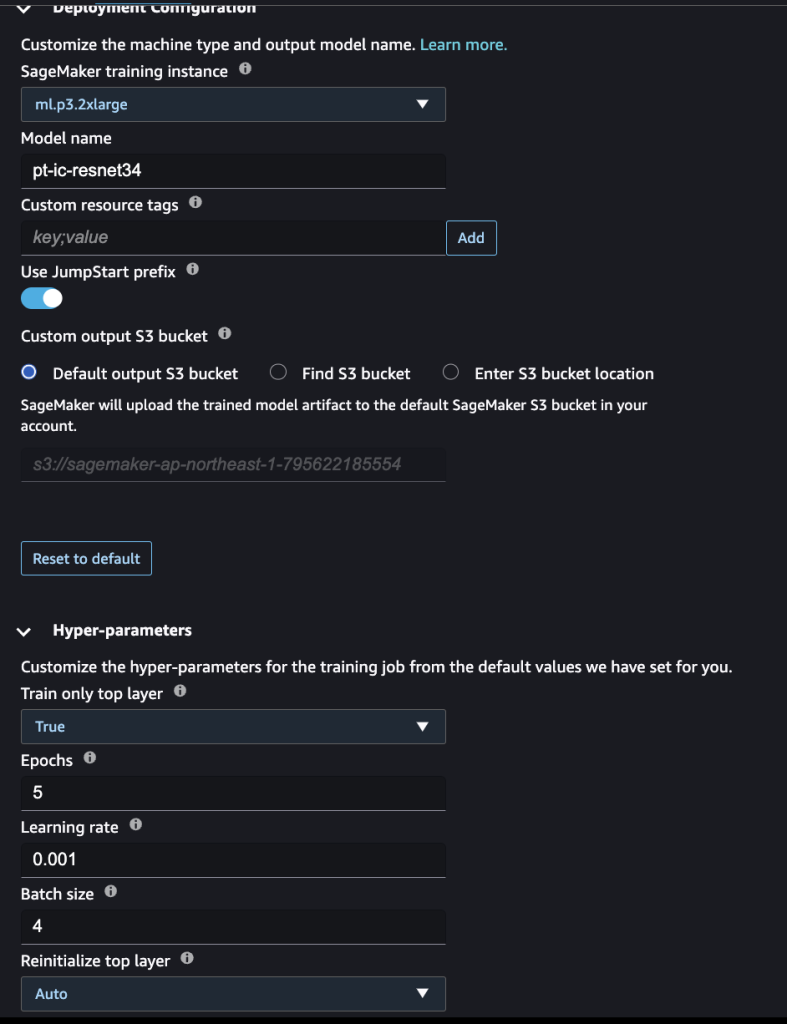
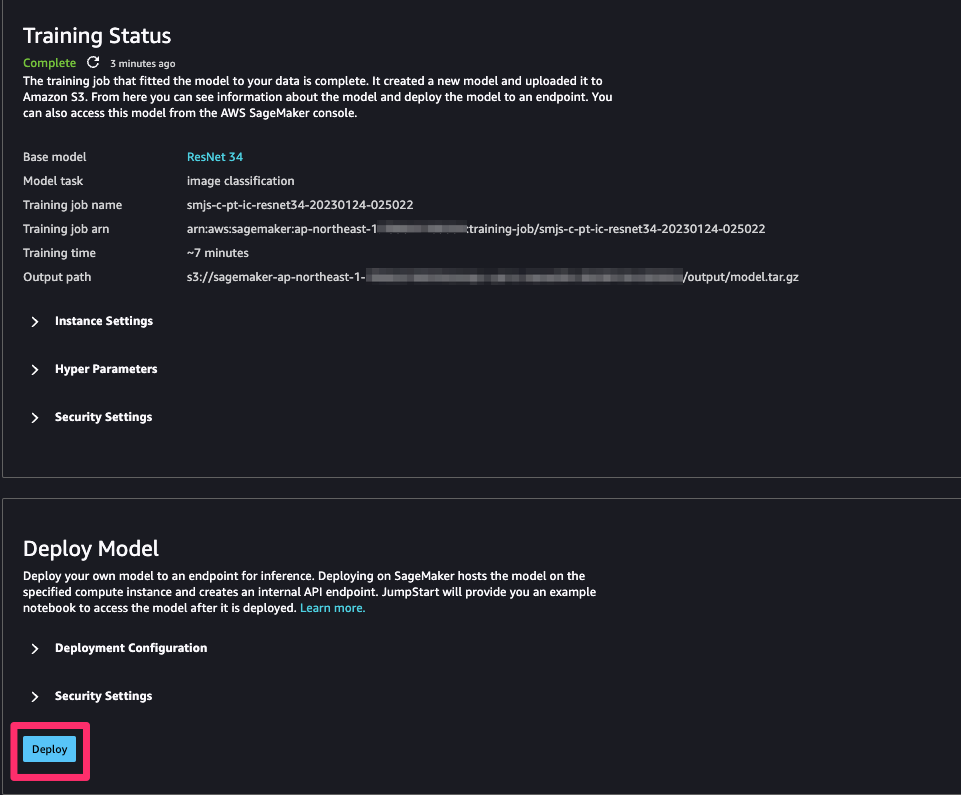
ステータスがCompleteになればトレーニング完了です。
今回は8分ほどで終わりました。
トレーニングしたモデルをデプロイして、推論する
新たにトレーニングさせたモデルをデプロイして、推論します。
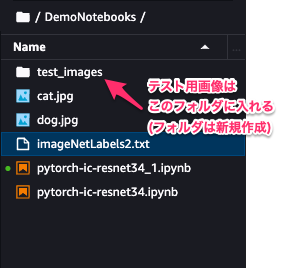
推論を行う前に、先ほど推論用に省いた画像を、SageMaker Studio内に取り込みます。
画像はドラッグ&ドロップで移すことができます。
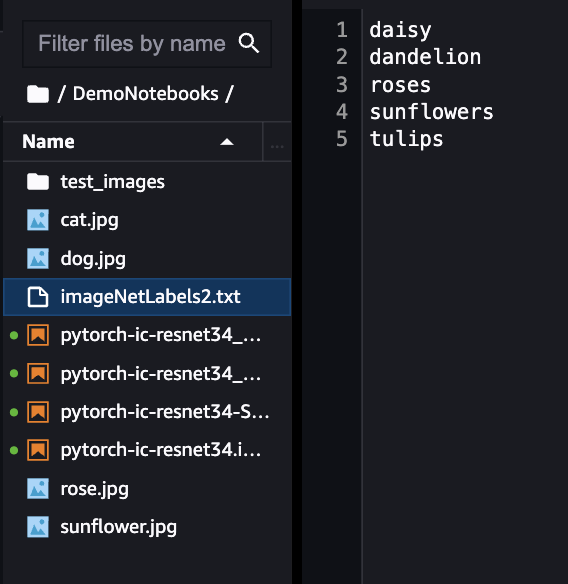
ラベルの修正も必要なので、imageNetLabels2.txtという名前のテキストファイルを新規作成し、学習させた画像のラベルを書きます。
※ラベルはアルファベット順で保存してください。
コードの修正も必要なので行います。
「Query endpoint that you have created with…..」とある下のセルを以下の内容に修正します。
import json
import glob
def query_endpoint(img):
endpoint_name = 'jumpstart-ftc-pt-ic-resnet34'
client = boto3.client('runtime.sagemaker')
response = client.invoke_endpoint(EndpointName=endpoint_name, ContentType='application/x-image', Body=img, Accept='application/json;verbose')
return response
def parse_prediction(query_response):
model_predictions = json.loads(query_response['Body'].read())
predicted_label = model_predictions['predicted_label']
labels = model_predictions['labels']
probabilities = model_predictions['probabilities']
return predicted_label, probabilities, labels
files = glob.glob("test_images/*")
images = {}
for file_path in files:
with open(file_path, 'rb') as fb:
images[file_path] = fb.read()
for filename, img in images.items():
query_response = query_endpoint(img)
predicted_label, probabilities, labels = parse_prediction(query_response)
display(HTML(f'<img src={filename} alt={filename} align="left" style="width: 250px;"/>'
f'<figcaption>Predicted Label is : {predicted_label}</figcaption>'))推論結果
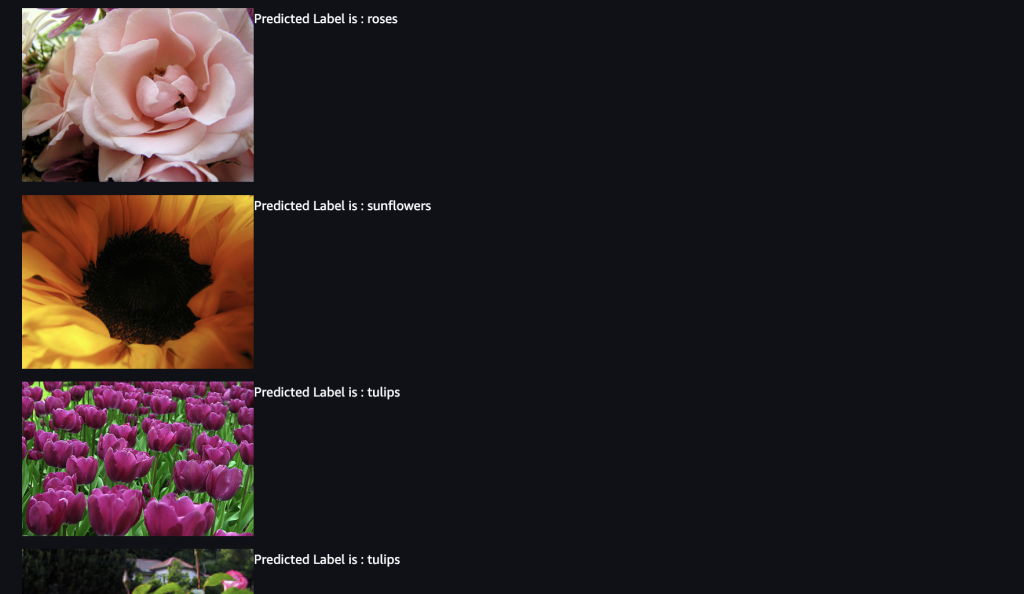
先ほど推論できていなかったバラやひまわりが、推論できるようになっていますね。
また他の画像も正しく推論できているようです。
まとめ
このように、SageMaker Jumpstart では機械学習初心者でも、簡単にファインチューニングを行うことができ、独自モデルを作ることができました。
オープンソースモデルを使用するための事前準備のコードを書く必要がなく、エンドポイントと画像を指定するだけで推論を行うことができます。これによって、迅速にかつ簡単に機械学習を始めることができます。
お掃除
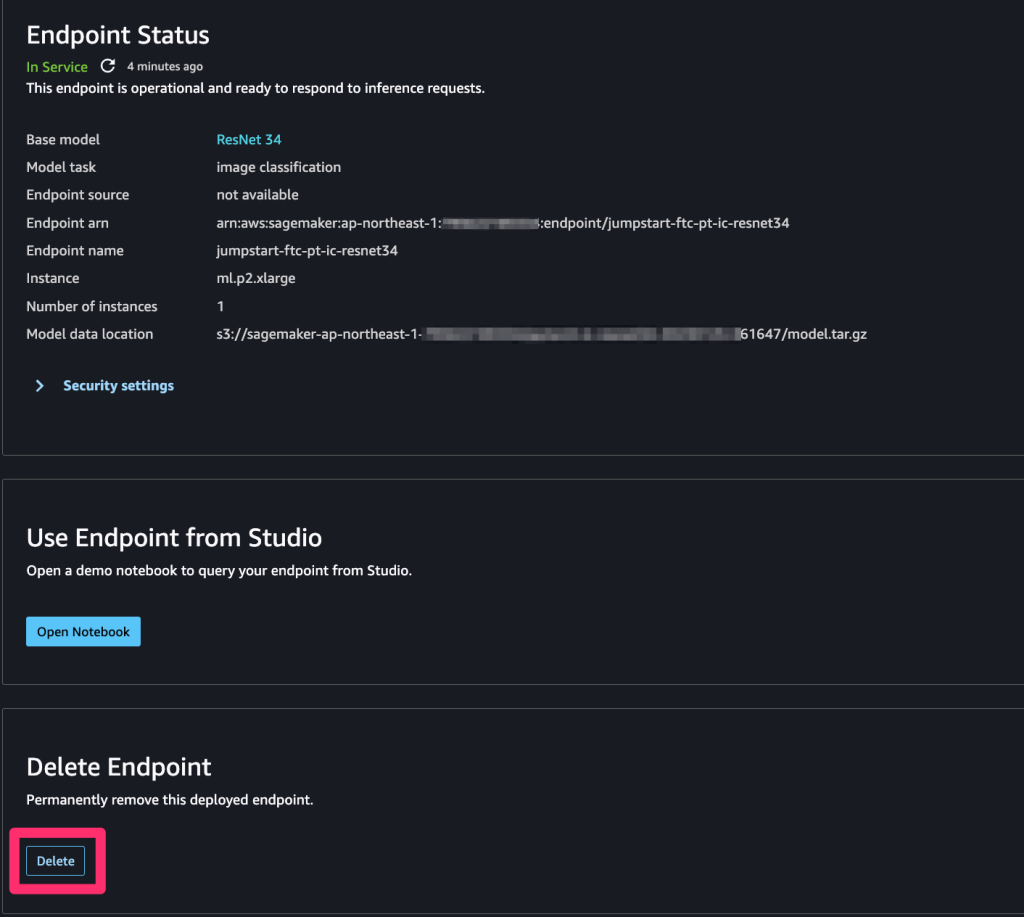
今回使用したインスタンスは、選択できるものの中から一番安いインスタンスを選択しましたが、それでも一時間で0.149USDかかり、1ヶ月に換算すると1万円を超える金額となるため、使用しないのであれば削除しましょう。
下記のDeleteをクリックすると削除されます。
今回は2つの推論インスタンスを立てたので、2つとも忘れずに削除しましょう。
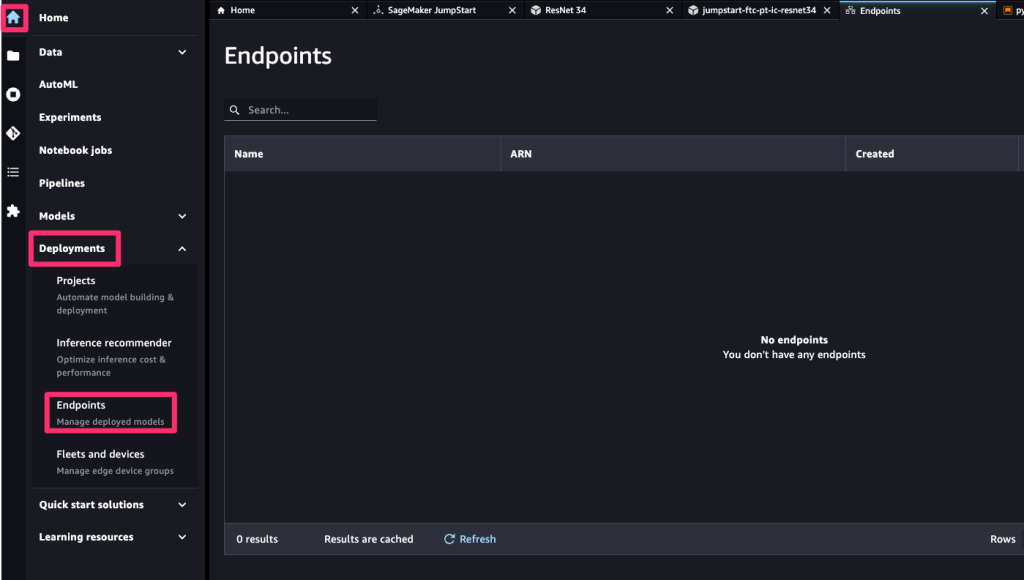
サイドバーのホームアイコンを開いて、Deployments > Endpointsを開いて「No endpoints」となっていれば、全ての推論用インスタンスが削除されています。
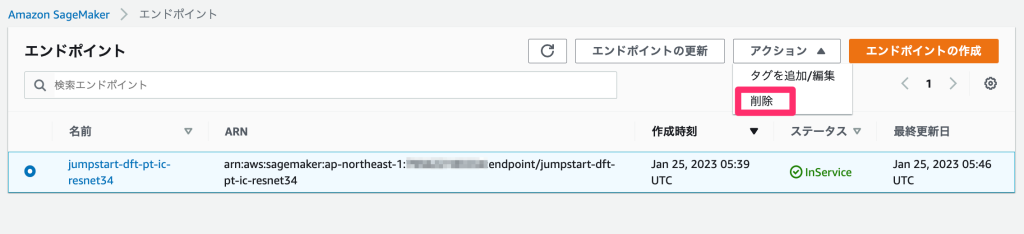
削除し忘れたエンドポイントがあった場合、Sagemakerのコンソールからも削除することができます。
サイドバーの「推論」 > 「エンドポイント」からエンドポイントの管理画面を開き、削除したいエンドポイントを選択して「アクション」 > 「削除」で削除することができます。
注意点
推論用インスタンスを削除しても、ノートブックは使うことができます。
ノートブック用のインスタンスが起動している状態ですと、こちらの利用料金も発生してしまうので、削除する必要があります。
赤枠の部分をクリックし、「shutdown all」を選択すると削除することができます。
※ このインスタンスで複数のノートブックを実行しているので、このインスタンスを削除すれば、今回使用したすべてのノートブックが使えなくなります。
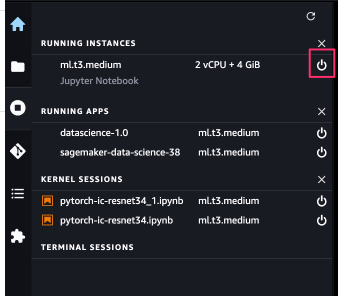
こちらの削除が完了すれば、全てのインスタンスが削除されます。




