YOLOXってなに
YOLOXは2021年に登場したYOLOシリーズの新モデルです。アンカーボックスを使用しないシンプルなモデルですが様々な工夫により推論速度や精度が向上しているそうです。
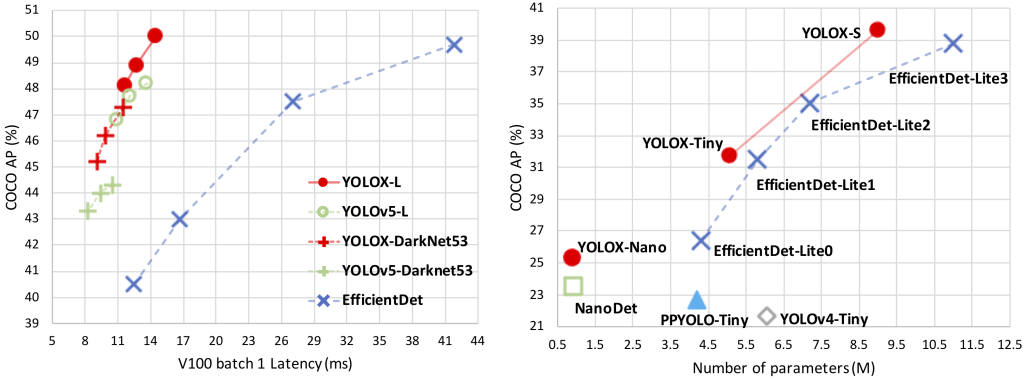
そこで今回はYOLOXで独自モデルを作ってみようと思います!また、作成したモデルをVieurekaカメラで動かしてYOLOv4とパフォーマンスを比較します。今回モデル学習に使用したデータセットは昨年参加したPanasonic様主催のコンテストVieureka camera App Challenge 2021で使用したものです。ちなみに、コンテストの様子はシリーズ化してブログ公開していますのでもしご興味があればそちらも併せてご覧ください。
<参考記事>
Vieurekaアプリコンテスト共催!IoTカメラアプリが完成するまで #1 ~キックオフからブレスト~
Vieurekaアプリコンテスト共催!IoTカメラアプリが完成するまで #1.5 ~Vieurekaのセットアップ~
Vieurekaアプリコンテスト共催!IoTカメラアプリが完成するまで #2 ~設計~
Vieurekaアプリコンテスト共催!IoTカメラアプリが完成するまで #3 ~開発~
Vieurekaアプリコンテスト共催!IoTカメラアプリが完成するまで #4 ~完成&納品~
なお、本記事ではAnchor-freeやSimOTA, Decoupled headといったYOLOXのモデル解説やソースコード解説は行いません。詳細は論文[YOLOX: Exceeding YOLO Series in 2021]やソースコード[Megvii-BaseDetection/YOLOX]を参照ください。
エッジデバイスでのAI活用
IoT.kyotoではエッジデバイスでのAI活用に力を入れておりエッジデバイスの一つとしてPanasonic様のVieurekaを採用しています。Vieurekaを活用した導入事例についてはこちらをご覧ください。

Vieurekaでは開発環境があらかじめ用意されているのでクラウド技術と組み合わせることで自由度の高いAIアプリを作成することが可能です。一方、エッジデバイスの特性上メモリやCPU, GPUといったリソースに制限があります。そのため推論速度がボトルネックにならないよう適切なモデルを選定する必要があります。
YOLOXには高い精度で推論できる巨大なモデルだけでなくエッジデバイスを考慮した軽量なモデルが用意されています。特にYOLOX-NanoはYOLOXのなかで最も軽量なモデルなのですがYOLOv4-Tinyより高いパフォーマンスが出ることが報告されています。
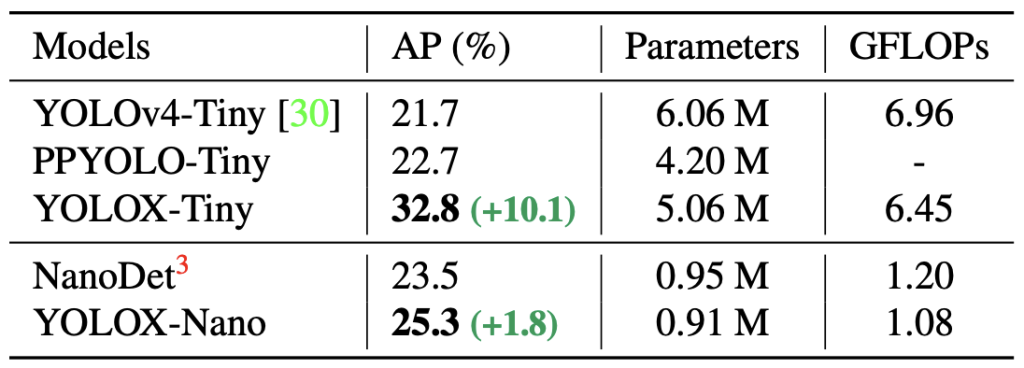
今回はYOLOX-Nanoを使って独自モデルを作成して同条件で作成したYOLOv4-TinyとVieureka上で推論速度を比較してみようと思います。
今回作成するモデルと検証環境
今回作成するモデルと検証環境です。
| 項目 | 詳細 |
|---|---|
| 使用デバイス | Vieureka VRK-C301(EdgeTPUやGPUは不使用) |
| 使用モデル | YOLOX-Nano |
| データセット | Vieureka App Challengeで使用したデータセット(50枚弱) |
| 物体検出対象 | 付箋, テープ, はさみ, ワイヤーケーブルの4つ |
モデル作成の流れ
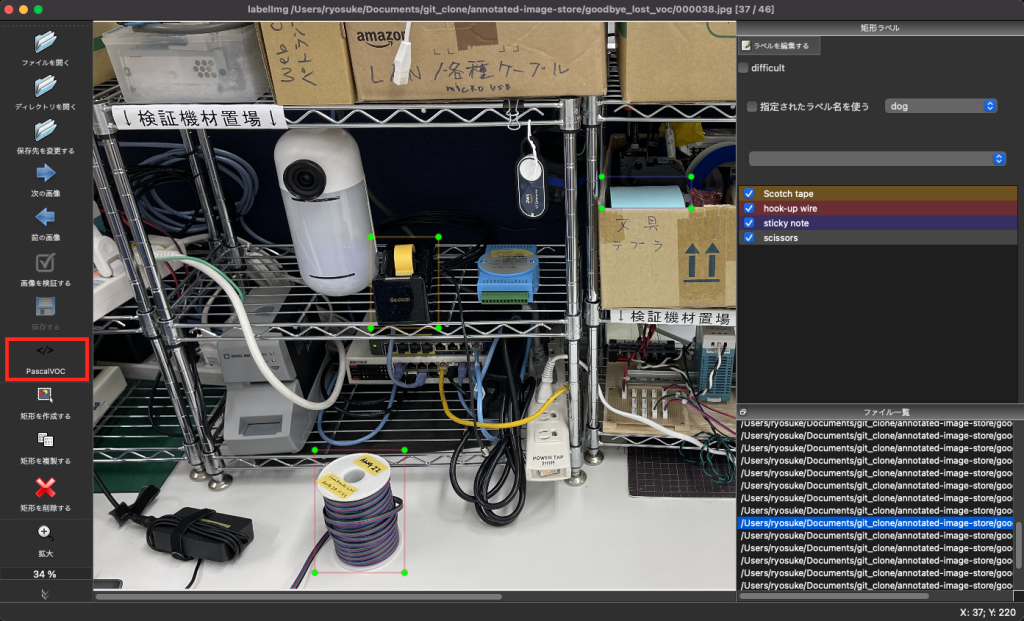
ラベリング
モデル作成の最初の作業は集めてきた画像のラベリングです。今回はデータセットの数が多くないので問題ありませんでしたが何百枚も画像がある場合は途方もない時間がかかります。正直この作業が一番大変です。
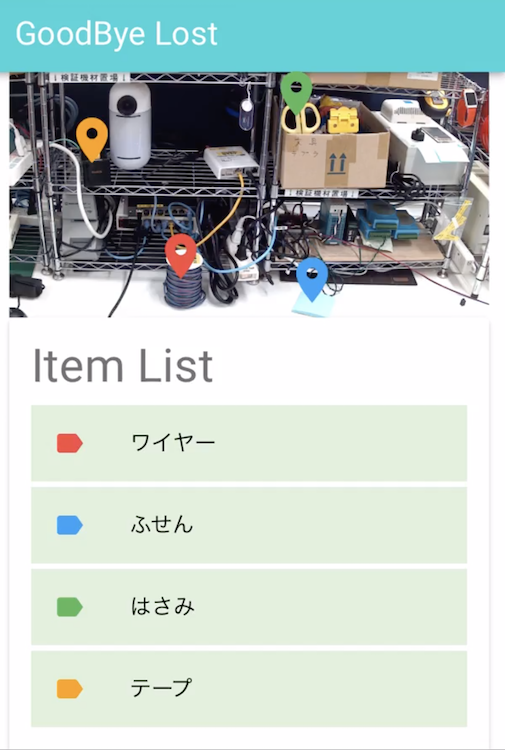
データセット
ラベリングが終わったら学習用のデータと検証用のデータに分けたりしてモデル学習ができるよう準備します。イメージはこんな感じです。
dataset
├── annotations ← train, validationのjsonファイル
└── images
├── train2017 ← train用の画像セット
└── validation2017 ← validation用の画像セット
configファイルの設定
YOLOX/exps/example/custom配下に各種モデルのconfigファイルがあるので必要に応じて修正します。今回はYOLOX-Nanoを使用するのでnano.pyを修正する必要があります。
# nano.pyファイル一部抜粋
# Define yourself dataset path
self.data_dir = "datasets/coco128" # 使用するデータセットのパス
self.train_ann = "instances_train2017.json" # train用アノテーションのパス
self.val_ann = "instances_val2017.json" # validation用アノテーションのパス
self.num_classes = 71 # 71クラスの分類
self.num_classesは最終的に分類されるクラスの数なのでデフォルトのままだとエラーになります。今回であれば4分類なので4に修正しないといけません。他にもデータセットのパスも修正する必要があります。
学習済みパラメータのダウンロード
学習済みパラメータをダウンロードします。
wget https://github.com/Megvii-BaseDetection/storage/releases/download/0.0.1/yolox_nano.pthモデルの学習
モデルの学習はtools/train.pyから簡単に実行できます。
python train.py \
-f nano.py \
-d 1 \
-b 16 \
--fp16 \
-o \
-c yolox_nano.pthモデル学習時に選択しているオプションの内容は下記のようになっています。
| オプション | 説明 |
|---|---|
| -f | cofigファイルのパス |
| -d | 使用するdevice番号 |
| -b | バッチサイズ、推奨値はGPUの数×8 |
| –fp16 | 混合精度トレーニング |
| -o | 学習時、最初にGPUメモリを確保する |
| -c | チェックポイントファイルの指定 |
モデルの結果
モデルの推論もtools/demo.pyで簡単にできます。
| class_name | result (%) |
|---|---|
| ワイヤーケーブル | 90.1% |
| 付箋 | 87.9% |
| はさみ | 82.5% |
| テープ | 88.3% |

高い精度で推論できていることがわかります。
モデルの変換
学習したモデルをさらに軽量なものにするためTensorflow Lite(以下、TF-Lite)に変換します。今回はONNX>Tensorflow>TF-Liteの順に変換していきます。
ONNX出力
ONNXへの出力はYOLOXに用意されているのでそちらを利用します。
python tools/export_onnx.py \
--output-name yolox_nano.onnx \
-n yolox-nano \
-f nano.py \
-c {MODEL_PATH}ちなみにONNXでの推論はdemo/ONNXRuntime/onnx_inference.pyを利用することで簡単に行えます。なお、ONNXのモデルファイルサイズは3.6MBでした。
!python demo/ONNXRuntime/onnx_inference.py \
-m {onnx_file_path} \
-i {test_image} \
-o ./ \
-s 0.3 \
--input_shape 416,416
ONNX>>TensorFlow
ONNXからTensorFlowへの変換はonnx-tfを利用します。なお、TensorFlowのモデルファイルのサイズ4.4MBでした。
pip install onnx-tf
onnx-tf convert \
-i yolox_nano.onnx \
-o yolox_nano_pb
TensorFlow>>TF-Lite
最後にTensorFlowからTF-Liteへの変換はtf-nightlyを利用します。
import tensorflow as tf
pip install tf-nightly
# 半精度浮動小数点数の量子化
converter = tf.lite.TFLiteConverter.from_saved_model('yolox_nano_pb')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quantized_model = converter.convert()
open('yolox_nano_float16_quantize.tflite', 'wb').write(tflite_quantized_model)
TF-Liteで推論してみます。ソースコードはdemo/ONNXRuntime/onnx_inference.pyを元にTF-Liteでも動くよう修正しています。

全く同じ推論結果が得られましたので無事変換することができました。なお、YOLOv4-TinyのTF-Liteのファイルサイズと比較すると8分の1以下になっていることがわかります。
| モデル名 | ファイルサイズ |
|---|---|
| YOLOX-Nano TF-Lite | 2.7MB |
| YOLOv4-Tiny TF-Lite | 23.6MB |
Vieurekaカメラでの検証
最後に検証です。変換したTF-Liteモデルを使ってVieureka上で推論速度を検証してみました。検証方法は各モデルで推論するアプリを作成して10回分の推論時間の平均を計測しました。推論画像はここまでの推論で使用した画像を一定間隔で送るよう設定しています。
| モデル名 | 推論時間 |
|---|---|
| YOLOX-Nano(float16) | 0.52sec |
| YOLOv4-Tiny | 1.042sec |
YOLOv4-Tinyの半分の時間で推論することができていますね。
まとめ
今回はYOLOXを使って独自モデルを作成しました。作成したモデルはVieureka上で動かすことができ、YOLOv4-Tinyの半分の時間で推論できることがわかりました。
なお、今回はPyTorchで学習したモデルをTFLiteに変換しましたがVRK-C301の新ファームでPyTorchを直接動かすことができるようになりました。モデルを異なるフレームワークに変換すると推論の精度が落ちたり、予期せぬエラーに繋がったりすることがありますのでこのアップデートはとても嬉しいですね。(詳細はこちらを参照ください。)

JAWS UG 京都にて登壇決定!
2022年8月7日(日)、「本気のAI」をテーマに京都、及びオンライン配信でJAWS UG京都を開催いたします。
当記事を書いたIoT.kyoto 若手メンバーも「物体検出モデルYOLOXとIoTの役に立つかもしれない話〜そもそもYOLOってなんですかという方へ〜」のタイトルで登壇いたします。
詳細や参加申込みについてはお知らせ記事をご覧ください。




