概要
Amazon SageMakerのビルトインアルゴリズムをいくつか使用して教師なしでの数値データの異常を分析し、結果を比較してみました。
SageMaker ビルトインアルゴリズムとは
ビルトインアルゴリズムは、Amazon SageMakerが提供する、一般的な機械学習タスクに対応するための最適化されたアルゴリズムのことを指します。これらのアルゴリズムは、高度なデータサイエンティストが利用するための機能から、初心者が機械学習を始めるための手順まで、幅広いニーズに対応しています。
ビルトインアルゴリズムの特長
1. 簡単に利用できる:機械学習の専門知識がなくても、高品質なモデルを作成することが可能です。
2. 最適化されたアルゴリズム:ビルトインアルゴリズムは、Amazonの広範なデータと経験に基づいて設計され、最適化されています。
3. スケーラブル:ビルトインアルゴリズムは、大量のデータを効率的に処理することができます。
Amazon SageMakerのビルトインアルゴリズムは、機械学習の専門知識がない人でも、高品質なモデルを簡単に作成することを可能にします。これらは最適化されており、さまざまなニーズに対応するための強力なツールです。
今回比較したモデルの解説
今回は以下の3つのビルトインアルゴリズムを使用して検証しました。
この3つを選んだ理由は、今回は教師なしでの数値データの異常分析を前提として検証を始めたので、教師なしに分類されている中で数値データの異常検知に適しているRCFとK-Meansを採用しました。また擬似的に教師なしで検証できそうだということでK-NNも採用しました。
それぞれの詳細な説明はリンク先記事にて紹介しています。
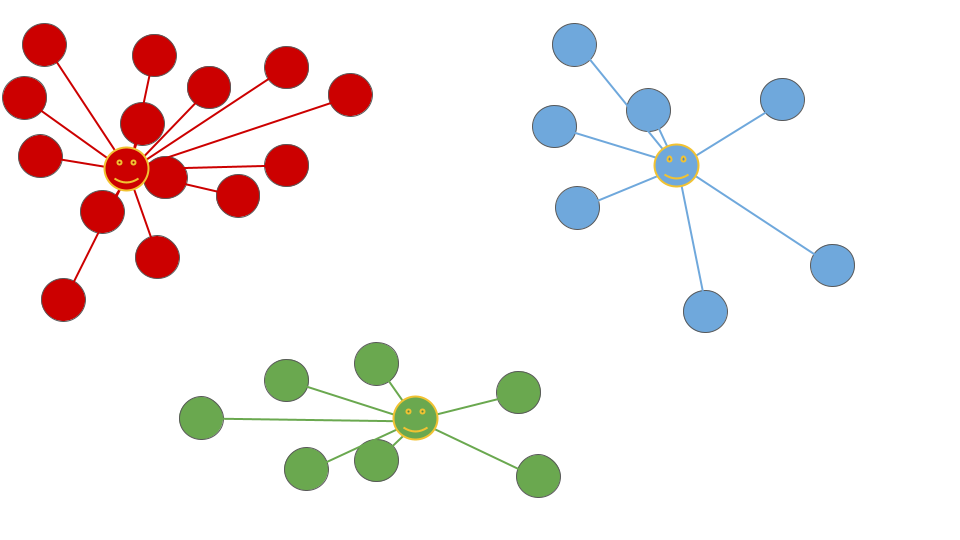
RCF
アンサンブル学習の一形態であり、異常検出やデータのランダム性を利用した異常検出などのタスクに用いられる、ランダムなカットを使用する森(forest)ベースのアルゴリズム
時系列データの異常検知におすすめの手法!Random Cut Forestでデータ分析
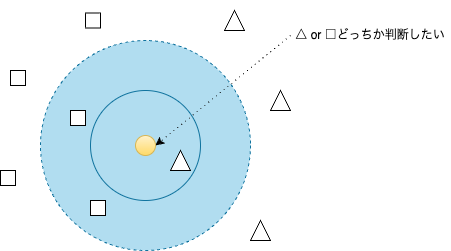
K-NN
新しいデータポイントを、距離の近いk個の既存のデータポイントの多数決に基づいて分類または予測するための分類・回帰アルゴリズム
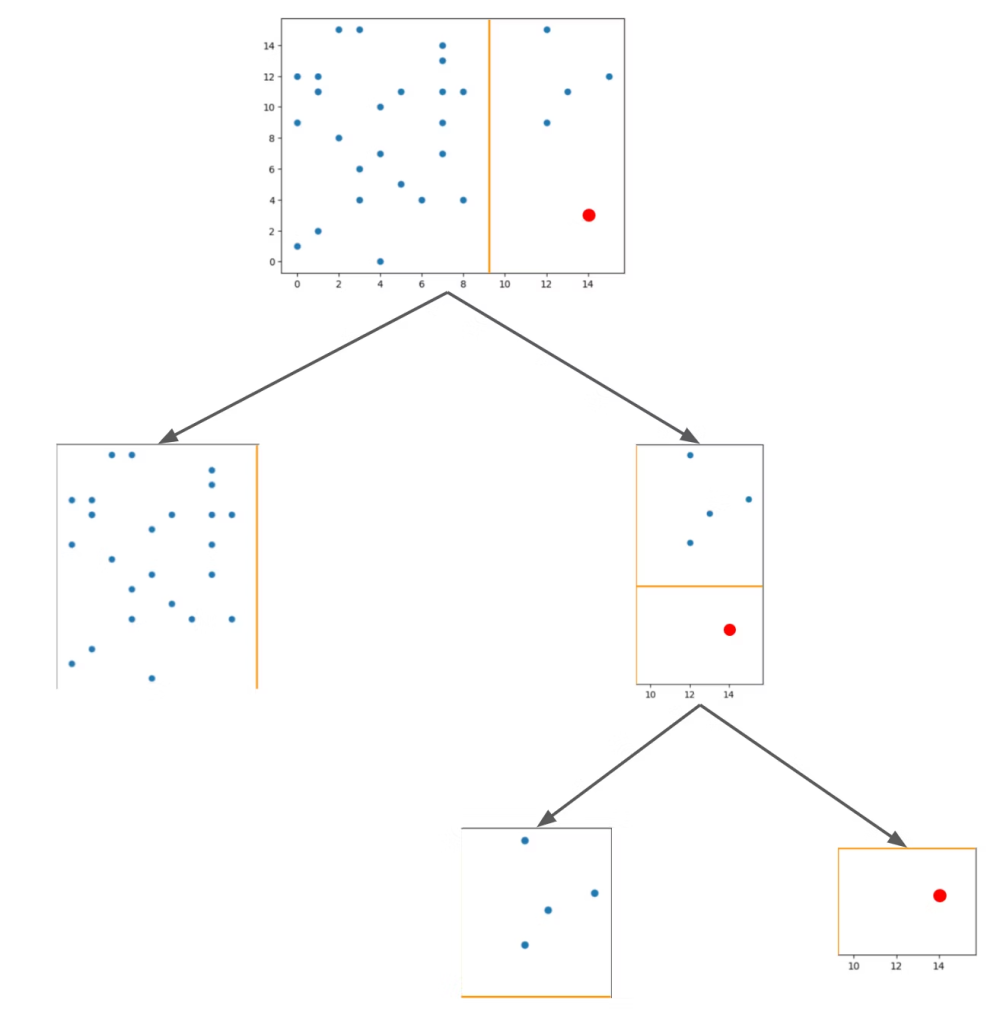
K-Means
データを事前に指定されたクラスタ数に分割するための非階層型のクラスタリングアルゴリズム
機械学習初心者がK-meansで数値データの異常分析を検証してみた
検証内容
検証したいデータの種類
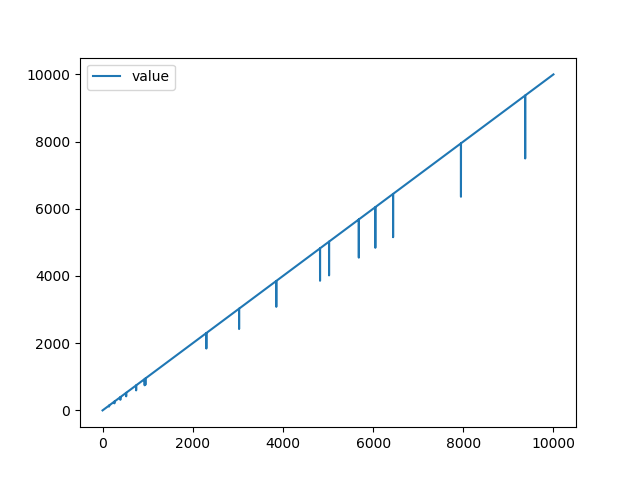
次のようなデータを使用してスパイク異常を検知できるか検証を行いました。
- 乱数(ダミー)
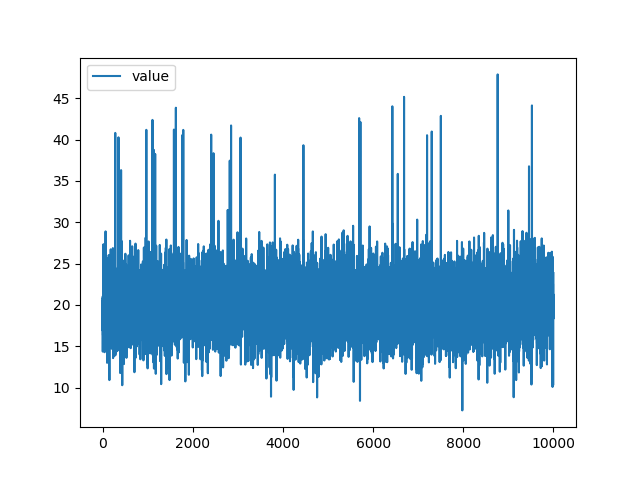
- 比例データ(ダミー)
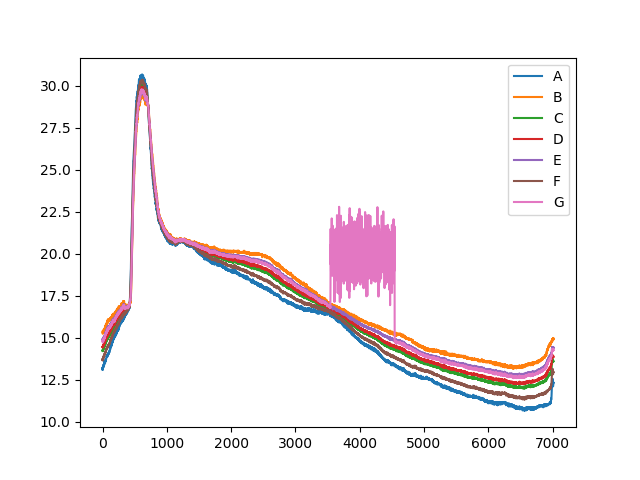
- 周期データ(実際の温度データ)
検証に用いるデータについて
乱数データと比例データは学習データ10000、テストデータ1000で実施しています。
周期データに関しては実際に会社のオフィスの温度を測って用意しました。
計測中特に異常気象は発生しなかったためテスト用の周期データの一部を人為的にスパイクさせています。
検証方法
今回はそれぞれのアルゴリズムに関して以下の手順で検証を実施しました
- Amazon SageMakerにてJupyter Notebook上に学習、テストを実行するプログラムを作成
- 用意した学習データでモデル作成
- 作成したモデルでエンドポイント払い出し
- 用意したテストデータを使用してテストを実施
- レスポンスデータをもとにcsv出力したものをプロットし異常検知の結果を確認
検証結果
異常検知の可否
| 乱数 | 比例 | 周期 | |
| RCF | ○ | ○ | ○ |
| K-NN | ○ | × | ○ |
| K-Means | ○ | × | × |
○:異常検知できた(適切に閾値を設定することでおおよそ100%判定可能)
×:異常検知できなかった
メリットデメリット
| メリット | デメリット | |
| RCF | 今回検証した全てのデータを検知可能 | モデルサイズが大きい |
| K-NN | モデルサイズが小さい | 異常のないデータでの教師あり学習が必須 |
| K-Means | モデルサイズが小さい データの規模に結果が左右されづらい | 手動で設定した初期値に結果が大きく左右される今回の検証では実用に耐えうる精度ではなかった |
まとめ
今回はAmazon SageMakerのビルトインアルゴリズムを使って数値データの異常分析を教師なし学習でできないか検証してみました。
今回検証した3つのモデルのうちRCFが一番パフォーマンスが良かったです。また、RCFはKinesisと連携することでリアルタイムに異常検知ができるように作られているのでリアルタイム推論をする場合、実装コストは大幅に抑えることができそうです。
一方でモデルサイズが大きいというデメリットがあり、運用コストに直結する部分でもあるのでユースケースによってはK-NNやK-Meansも選択肢になりえるかもしれません。
今回はダミーデータを使ったモデル単体での比較検証でした。モデルを作って終わりではないため、実運用を考慮したうえでどの選択肢が最適か考えていく必要がありそうです。




