概要
普段の業務ではIoTにより様々なデータがたくさんクラウド上に蓄積されます。
(主に時系列関係をもった数値データ)
そこで、蓄積されたデータを有効活用するために時系列データを用いた異常検知を試してみることにしました。
時系列データの異常検知を得意としているランダムカットフォレスト(RCF)を使ってどれくらいの精度で異常検知ができるのか検証しました。
今回はAmazon Sagemakerのビルトインアルゴリズムを使用しています。
※ここでいう「異常検知」とは、データの前状態(周期状態)を考慮してデータがスパイクしている部分を検知することを指しています。
RCFとは?
RCFは教師なし学習の一種で、データ内の異常なデータを検出するためのアルゴリズムです。
今回やろうとしている異常検知にはピッタリですね。
色々と調べてなんとなーく理解したのですがうまくまとめる力がないのでchatGPT先生に聞いてみました…
ランダムカットフォレストは、多数の木を作成し、それぞれの木でデータを分割します。データは、ランダムに選ばれたサンプルによって分割され、それぞれの木で異常スコアを計算します。異常スコアは、多くの木で深さが浅くなることで高くなり、異常なデータポイントを検出することができます。このアルゴリズムは、大量のデータを扱うことができ、高次元データにも対応できます。ランダムカットフォレストは、ハイパーパラメータの調整が比較的容易で、他のアルゴリズムとの組み合わせも有用です。
だそうですww
私のなんとなくの理解と合致しているので間違った情報ではないと思ってます…
RCFを学ぶ中でisolation forestの派生系ということがわかったので(参考記事)、isolation forestについても調べてみました。(RCFの理解の前にこちらを知ったほうがイメージしやすかったです)
isolated forestとは
isolation forestは異常検知をするためのアルゴリズムです。
データ郡をグラフにプロットしてあるターゲットのデータ点について考えたとき、
ランダムに2分割します。これをターゲットのデータ点が一つになるまで実施します。
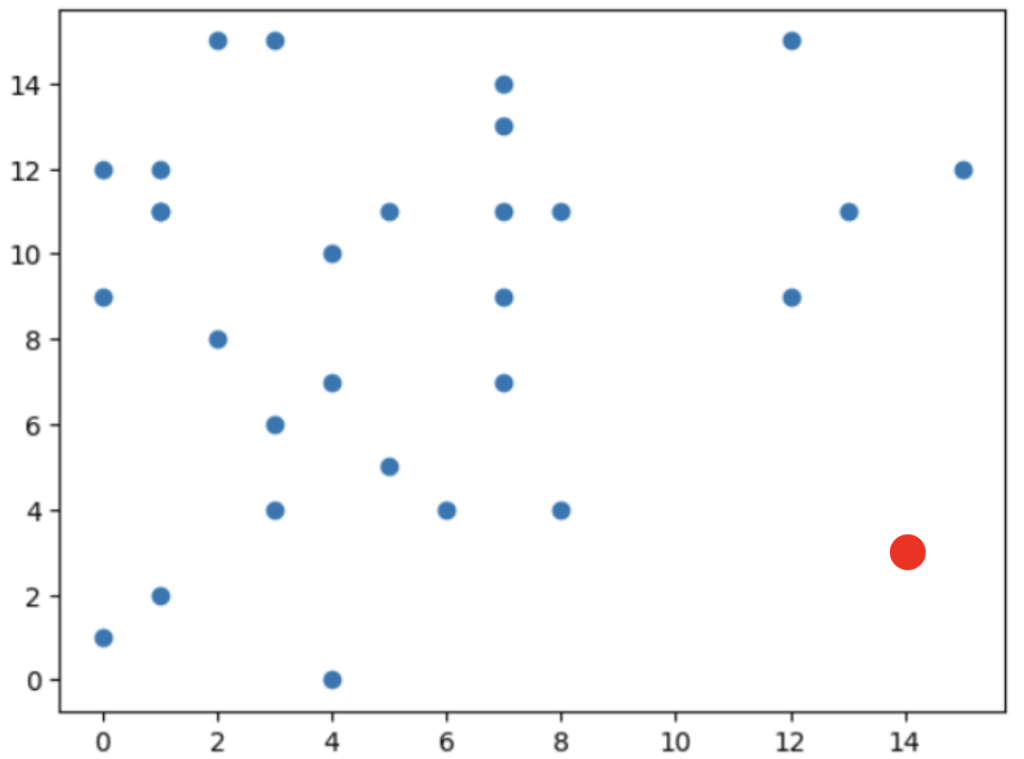
例えば、上記のグラフのうち赤点をターゲットとしたとき、以下のような流れになります。
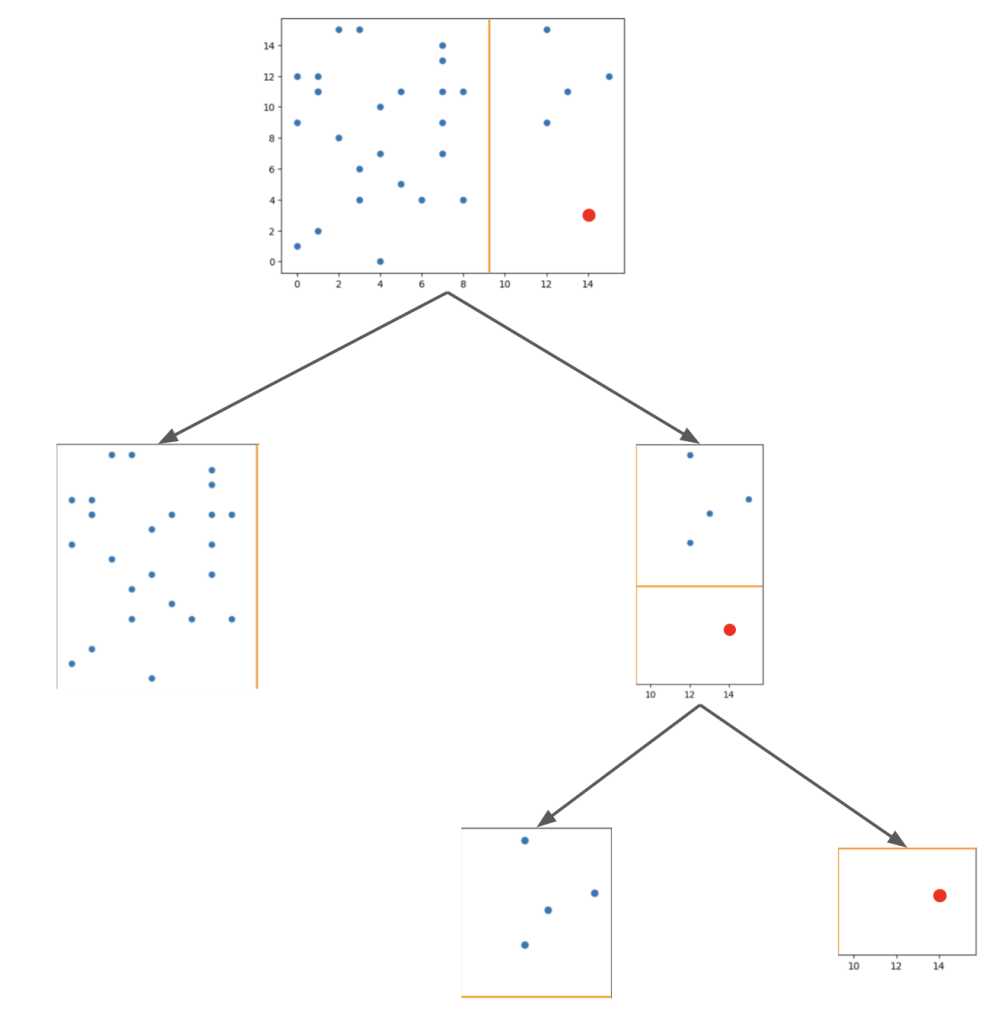
この木構造が浅いほど(= 他の点から離れている)異常という判断になります。
RCFでの周期データ推論について
RCFは周期データを使った異常検知を得意としています。(と言われています)
RCFで周期データを扱う際には事前にshingling処理をします。
shingling処理とはデータ全体を周期ポイントごとに区切ることです。
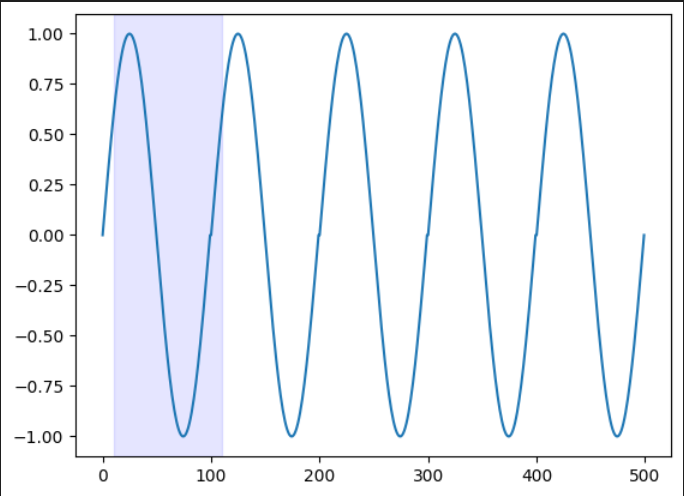
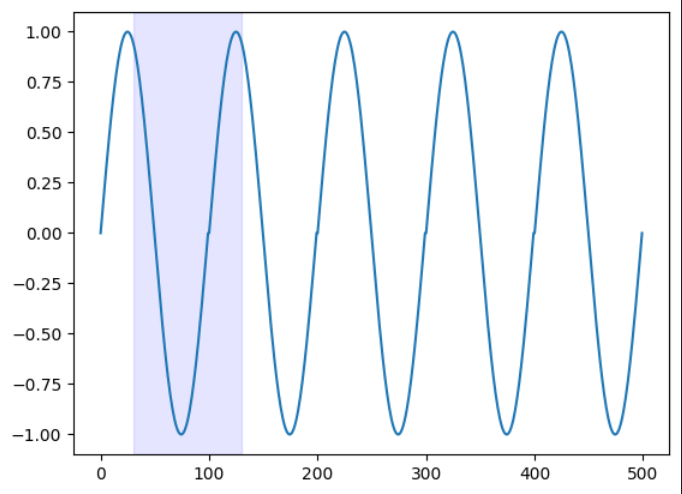
たとえば、1周期100ポイントのsin曲線が5周期あるとします。(下図)
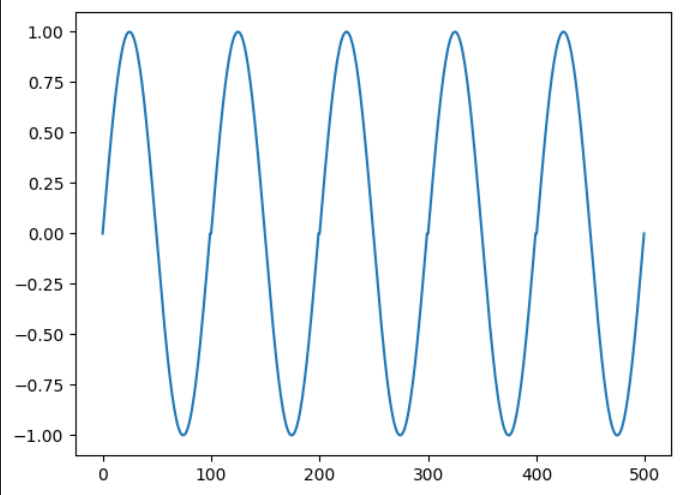
この場合、shingle sizeを100として
1つの数値を1つのデータとして扱うのではなく、
連続する100の数値を1つのデータとして扱い、特徴を得ます。
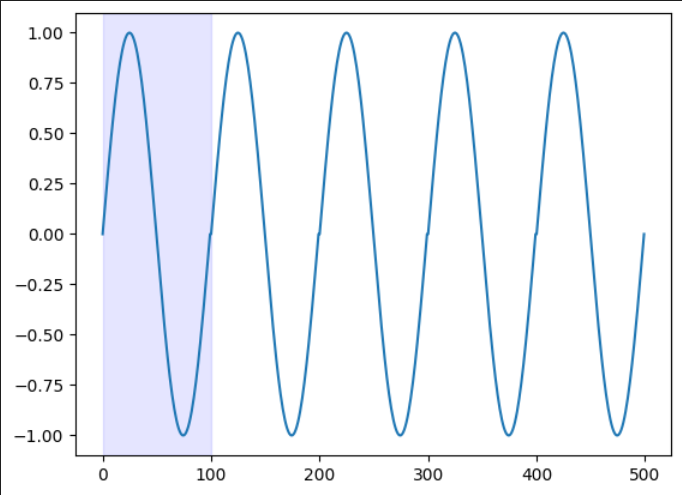
下図の青部分が一つのデータの塊となります。
1ずつ青部分をずらしていくことでshingleデータを作成します。
 |  |  | ・・・ |
データを点ではなく、線として学習することで前後関係や周期性を考慮した学習をすることが可能になります。
検証内容
今回は時系列データの中でスパイクしたデータを異常として検知できるのか、検証しました。
用意したデータは以下の4種類です。
それぞれ学習については異常値を含むものと含まないものの2種類のデータを用意し、それぞれを使って学習して結果を比較しています。
- 比例データ
- 正規乱数
- sin曲線 + 乱数(周期データ)
- 温度データ(周期データ)
温度データ以外は擬似的に作成したものです。
温度データは実際に温度センサーを用いて取得した温度データを元に学習・推論しました。
また、異常値については人為的に作成しています。
データ数について
比例データ、正規乱数、sin+乱数については学習データ10000、テストデータ1000で実施しています。
また、sin+乱数のデータ周期は100ポイントとしています。
温度データのみ学習データ49105、テストデータ49105としています。
また、周期は7015ポイントです。
結果について
まず、結果グラフの線の色は以下の意味を表しています。
黄緑:テストデータ
サーモン:推論結果
各結果グラフには黒点がありますが、それが異常と判定された箇所です。
閾値は以下を計算して上限・下限を求めています。
- 上限
異常値(score)平均値 + 3 * score標準偏差
- 下限
score平均値 – 3 * score標準偏差
比例データ
それぞれの学習モデルで推論したところ、以下の結果になりました。
いずれも異常値が問題なく検知できました。
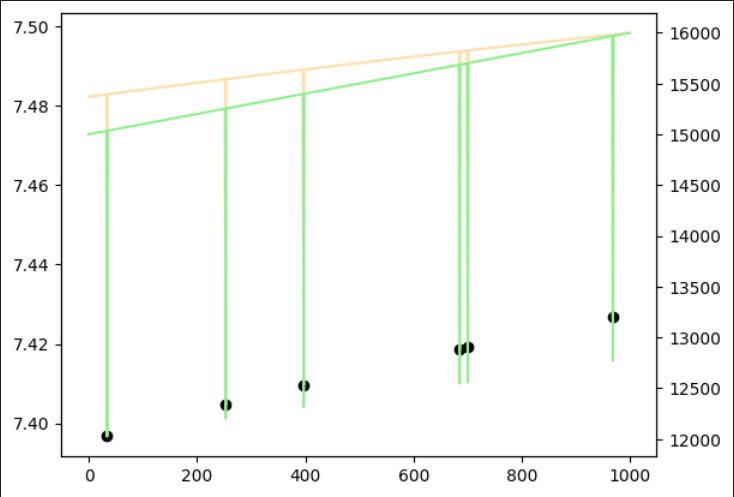 | 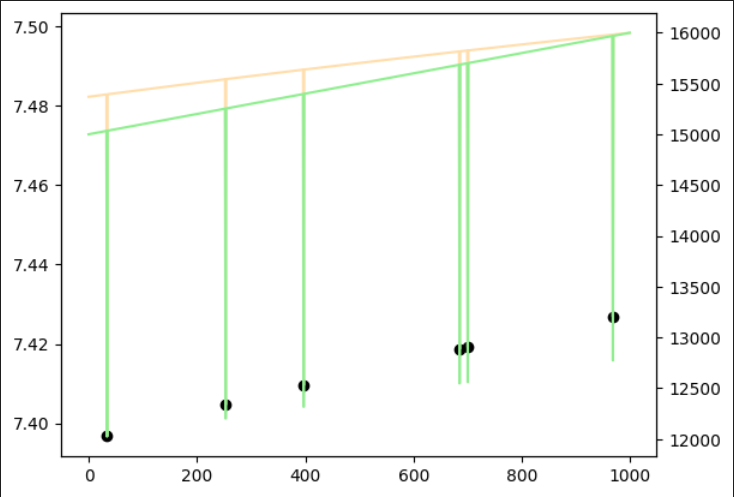 |
| 異常あり学習 | 異常なし学習 |
正規乱数
異常あり学習・異常なし学習ともに1点偽陽性があるものの偽陰性はなく、すべての異常点を検出することができました。
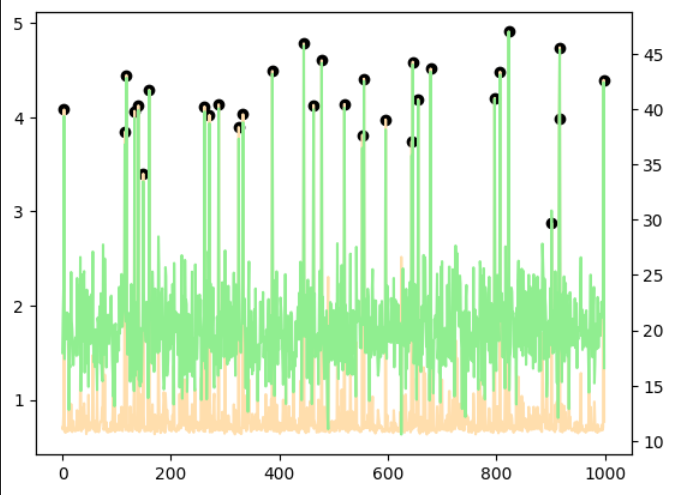 | 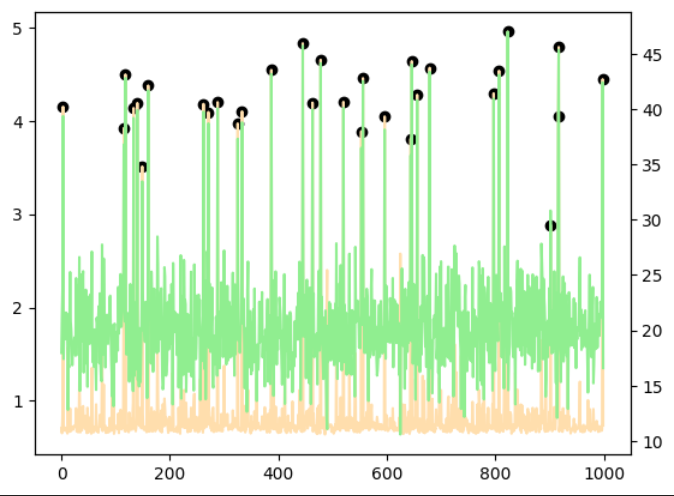 |
| 異常あり学習 | 異常なし学習 |
sin曲線 + 乱数(周期データ)
こちらは異常点が少し分かりづらいので異常点を赤丸で囲っています。
1つ目の赤丸はスパイクではなく、一定期間数値に変化がない、という異常を表しています。
周期データは起点から周期数(今回は100)だけの範囲のデータを見て、それに対する異常度を表しています。
そのため、異常点が現れるより前の点で黒点が発生しています。
作成した異常部分をもって異常と判断しているのかはわかりかねますが、
黒点の位置からおそらくうまく検出できているのかなと思います。
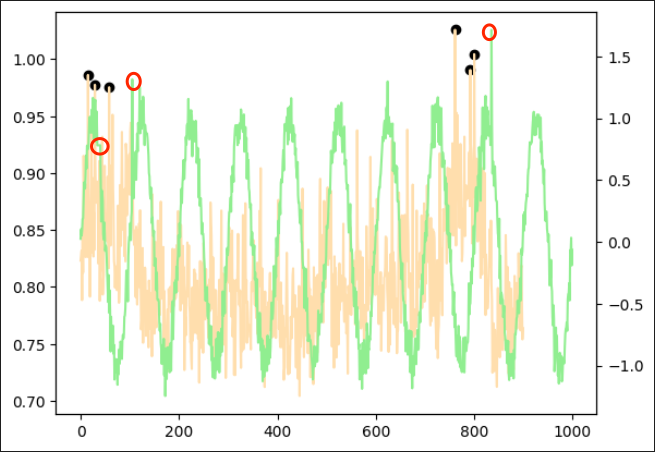 | 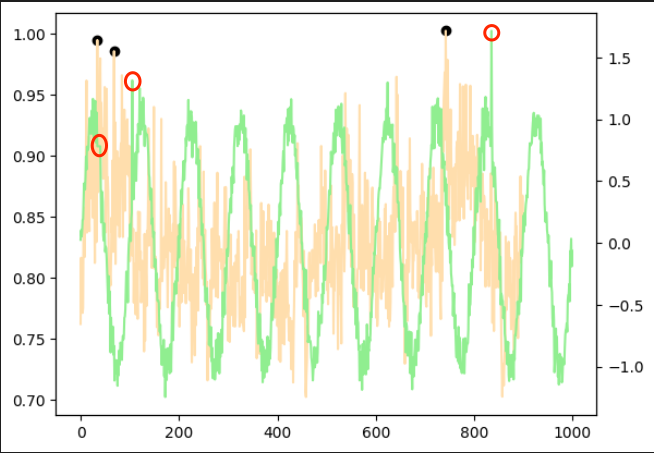 |
| 異常あり学習 | 異常なし学習 |
実際に取得した温度データ(周期データ)
こちらもうまく異常値を検出することができました。
(点ではなく範囲で推論しているため、異常判定されている位置は実際の異常点よりずれています)
ただし、モデルのファイルサイズ(model.tar.gz)が大きくなってしまい、sagemaker上にデプロイする際、
他の検証ではインスタンスサイズはxlargeで問題なかったのですがこのデータのみ4xlargeにする必要がありました。(メモリ不足でデプロイエラーに…)ですので実際に利用する際は費用対効果を十分に考える必要がありそうです。
おまけとして、試しにshingling処理をせずに学習もしてみました。shingling処理をしない場合は周期性や前後関係を見て推論することができないため、どの周期でも同じタイミングで発生しているスパイクを異常とみなしてしまっていました。shingling処理をすることでうまく周期性を考慮した推論ができていることがわかります。
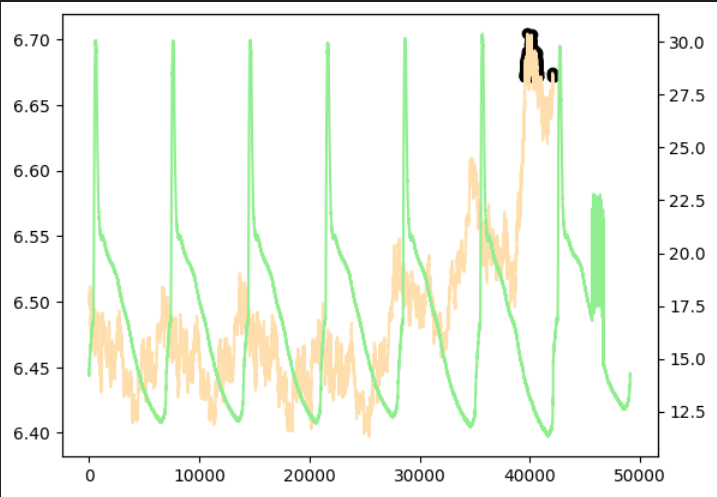 | 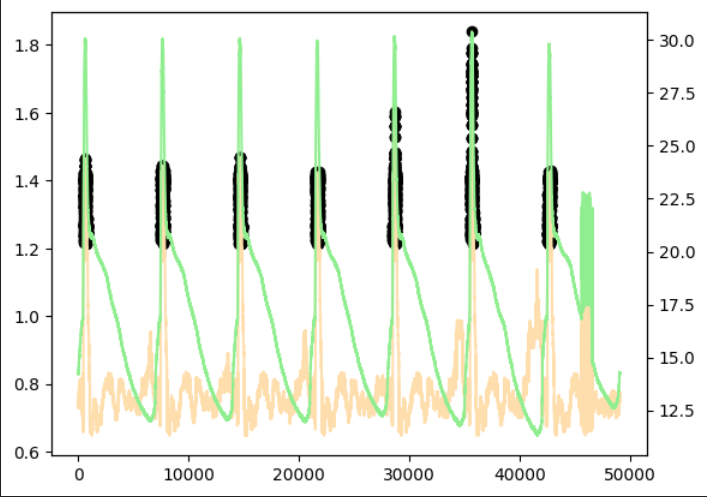 | 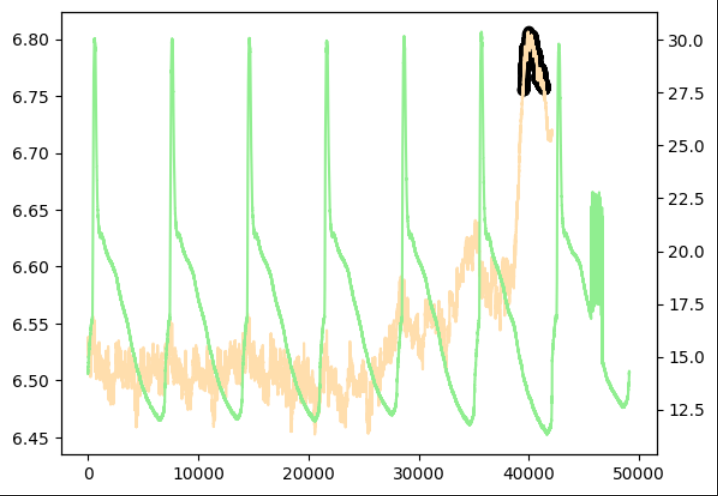 |
| 異常あり学習 | 異常あり学習 (shingling処理なし) | 異常なし学習 |
考察
今回の検証では一部偽陰性はあったものの、精度は実際に使用できそうなものでした。
ただし、sagemaker上でデプロイした際にインスタンスサイズを大きくしなければいけないケースもあるため、実際に運用する際は費用対効果やコストダウンするにはどうしたらいいかを考慮する必要もあると考えます。
パラメータチューニングを特にすることなくこれだけの精度が出たので大変使いやすいモデルだと感じました。また、チューニングが必要だったとしてもパラメータは2つ(num_treesとnum_samples_per_tree)で済むためパラメータが複数あって複雑なモデルに比べると使いやすいかなと思います。
まとめ
今回はsagemakerのビルドインアルゴリズムを用いてRCFを使った時系列データの異常検知をやってみました。
工場の部品の振動変化や設備の温度変化から自動で異常を検出してアラートを挙げられるようになったら部品の交換頻度の削減や故障の予知保全につながるのではと期待が膨らみました。




