はじめに
異常検知は大量のデータから通常とは異なるものを検出する技術です。異常検知には様々な手法が応用されており、近年ではAIや機械学習モデルを活用した新たな手法が次々と登場しています。
IoT.kyotoでも時系列データに焦点を当てていくつかの機械学習モデルを検証してきました。
今回、Random Cut Forest(RCF)を使った異常検知デモを作成しましたのでその中身についてご紹介したいと思います。デモについてはこちらのブログで公開していますので併せてご覧ください。
アルゴリズムの詳細についてはここでは言及しませんので興味のある方はGuha et al. (2016)をご参照ください。
Random Cut Forestとは
データセット内の異常なデータポイントや外れ値を検出できる機械学習アルゴリズムです。Random Forestアルゴリズムをベースとした教師なし学習であり、各データポイントで異常スコアを算出します。
算出された異常スコアの値が高いほどそのデータポイントは異常である可能性が高いと考えますのでこのスコアを使って異常を定義します。
Pythonでの実行
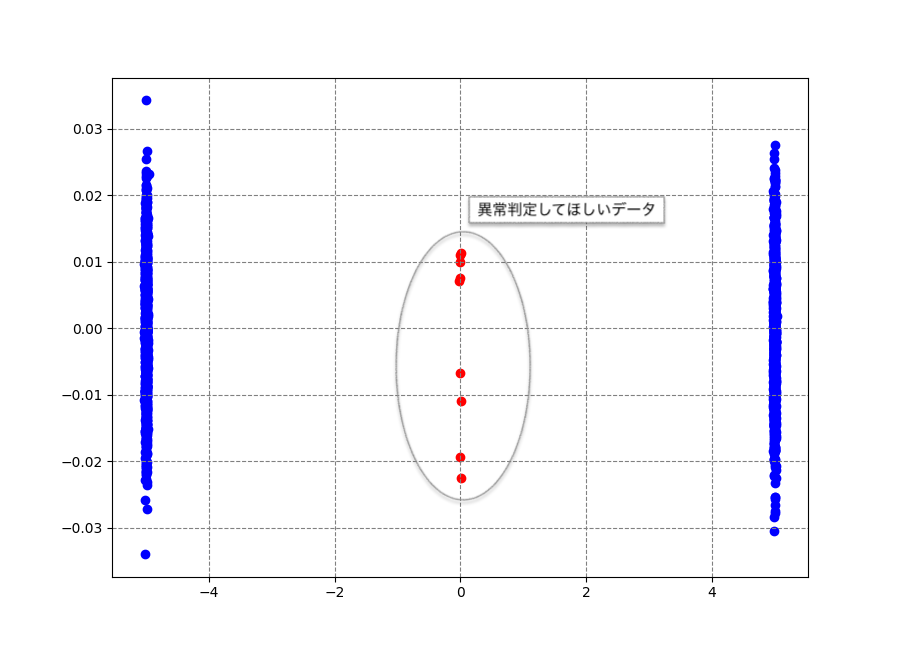
PythonでRandom Cut Forestを実行するにはrrcfライブラリを使用します。公開されているサンプルコード(Batch anomaly detection)を参考にしながら下図のデータについてスコア算出してみます。
算出したスコアをz軸にプロットした3Dグラフとy-z軸で切り取った2次元グラフをそれぞれ描画すると下図のようになります。
 | 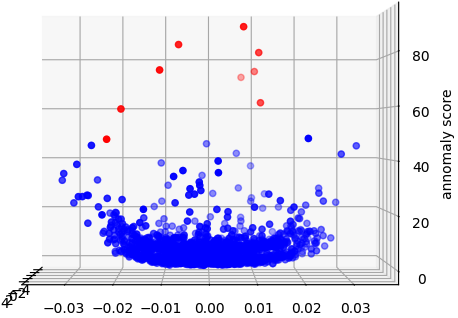 |
異常データとして手動追加したデータポイントのスコアが高くなっていますね。それだけでなく正常データについても中央付近と端っこ付近のデータの一部でもスコアが高いことがわかります。閾値の設定によってはこの辺りが偽陽性になりやすそうですね。
アーキテクチャ
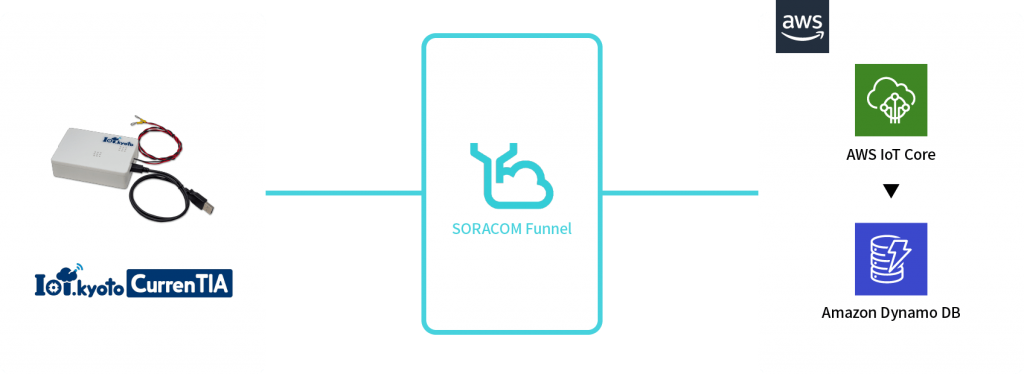
ここからは今回作成したデモの詳細について触れていきます。まずは今回作成したアーキテクチャの紹介です。シンプルなサーバレスアーキテクチャを使っていて可視化画面からデータを取得する際のLambda上でRandom Cut Forestを実行しています。

なお、DynamoDBに保存されているデータはIoT.kyoto CurrenTIAで取得した温度データを10秒間隔でSORACOM Funnel、AWS IoT Core経由でAmazon DynamoDBへ保存したものを使用しています。
なぜLambdaで実行するのか
AWS上でRandom Cut Forestを利用する場合、Amazon SageMakerやAmazon Kinesis Data Analyticsを実行環境にすることが多いと思いますが、いずれもランニングコストが高いことがネックでした。サーバレスなアーキテクチャで低コストで手軽に異常検知が実現できないかと考えて今回のアーキテクチャを採用しました。
実装
ここからは実装の詳細について触れていきます。
先述したrrcfですが、デフォルトではLambdaにインストールされていないのでそのままでは実行できないのでLambda Layerを使用する必要があります。
Lambdaの中で実施している処理フローは以下です。
- DynamoDBからデータ取得(説明省略)
- データの整形
- treeの作成(rrcf使用)
- スコア計算(rrcf使用)
- 閾値の計算
- 各データポイントの異常判定(説明省略)
ここからは各処理についてポイントを絞って説明していきます。
2. データの整形
DynamoDBから取得したデータのうちrrcfで使用するデータを抽出・加工してnumpyへ変換しています。後続の処理がnumpy前提のためnumpyへの変換は必須だと思います。
data = []
for item in data_res:
data.append([float(item["COL_NAME"])])
X = np.array(data)
3. treeの作成 〜 4. スコア計算
ここがメインの処理です。rrcfを使用して異常スコアの計算まで行います。ただ、何も考えずにサンプルコードをそのまま実行すると実行時間に問題があることがわかりました。
num_trees = 100
tree_size = 256
sample_size_range = (n // tree_size, tree_size)
# Construct forest
forest = []
while len(forest) < num_trees:
# Select random subsets of points uniformly
ixs = np.random.choice(n, size=sample_size_range,
replace=False)
# Add sampled trees to forest
trees = [rrcf.RCTree(X[ix], index_labels=ix)
for ix in ixs]
forest.extend(trees)
処理するデータ件数が処理時間にどの程度影響するのかLambda(デフォルトスペック)の実行時間計測して調査しました。なお、tree_sizeはデータ件数が20以下の場合はデータ件数の数値をそのまま、データ件数が20~256のときはデータ件数を3で割った商の値を採用しています。
| データ件数 | データ取得時間 | Tree作成時間 | スコア計算時間 | 合計 | 異常検出可否 |
|---|---|---|---|---|---|
| 10 | 0.2114 | 1.5947 | 2.1598 | 3.9660 | × |
| 50 | 0.2497 | 2.3025 | 2.1209 | 4.6730 | × |
| 100 | 0.2554 | 4.8409 | 2.7411 | 7.8374 | △ |
| 250 | 0.3688 | 9.5814 | 3.7209 | 13.6712 | △ |
| 500 | 0.4867 | 9.9379 | 3.6185 | 14.0431 | ◯ |
| 1000 | 0.8231 | 24.9798 | 5.1596 | 30.9625 | ◯ |
| 2500 | 1.7249 | 26.7606 | 5.4385 | 33.9240 | ◯ |
データ件数が100件程度あれば単純なスパイクは異常判定できそうでしたが、データ更新、画面更新のたびに8秒かかるので正直使えないです・・・
今回は1次元データに対する異常検知であり、処理するデータ件数もそこまで多くないので下記部分は精度に影響を及ぼさないのでは?と思いました。
# Select random subsets of points uniformly
ixs = np.random.choice(n, size=sample_size_range,
replace=False)
そこでnum_trees=1, tree_size=データ件数として再度検証してみると実行時間、精度ともにデフォルトのパラメータ値よりも良くなりました。
| データ件数 | データ取得時間 | Tree作成時間 | スコア計算時間 | 合計 | 異常検出可否 |
|---|---|---|---|---|---|
| 10 | 0.2653 | 0.0754 | 0.0001 | 0.3407 | × |
| 50 | 0.3111 | 0.1016 | 0.0003 | 0.4130 | △ |
| 100 | 0.3248 | 0.1809 | 0.0005 | 0.5062 | ◯ |
| 250 | 0.3775 | 0.3370 | 0.0013 | 0.7158 | ◯ |
| 500 | 0.5662 | 0.3598 | 0.0223 | 0.9483 | ◯ |
| 1000 | 0.8994 | 0.5601 | 0.1193 | 1.5788 | ◯ |
| 2500 | 1.7748 | 0.7571 | 0.2228 | 2.7547 | ◯ |
データ件数が多いケースでは既存のパラメータの値は実行時間、精度ともにバランスがよいが、データ件数が極端に少ないケースや次元が低いケース、異常が単純なケースでは精度向上への寄与度は高くない、あるいは逆効果の可能性があるのではないかと思います。
追加検証するにはパラメータチューニングが必要になるので今回はひとまずnum_trees=1, tree_size=データ件数として実装することで実行時間の問題を回避することにしました。
5. 閾値の計算
最初は「3シグマのルール」を採用して平均値+3×標準偏差を閾値に設定していました。しかし、偽陽性が多かったので調整を重ねて最終的に今回は平均値+5×標準偏差の値を閾値として設定しました。
# 5σの計算 avg_codisp_arr = np.array(avg_codisp) avg_codisp_arr_mean = np.mean(avg_codisp_arr) avg_codisp_arr_std = np.std(avg_codisp_arr) threshold = avg_codisp_arr_mean + avg_codisp_arr_std * 5
閾値の設定は難しく、明確な答えがないのが現状かなと思います。データが正規分布に従うケースでは99.7%以上のデータが平均値±3×標準偏差の範囲に収まりますので「3シグマのルール」を採用するとうまくいくことが多いかと思います。
しかし、正規分布に従わないケースではこれは正しくありません。分布の仮定を大きく緩めたチェビシェフの不等式では88.8%ですのでカバー率は9割未満となります。もし同不等式で95%以上のカバー率を出すには5シグマが必要になります。
最後に
今回はRandom Cut Forestを使って作成した異常検知デモの中身についてご紹介させていただきました。
低コストなサーバレス環境で異常検知を実装するためにはまだまだ課題があります。周期性を考慮した異常検知の実現を目先の課題として引き続き研究を進めていきたいと思います。

AIカメラを使ってお客様の課題解決をお手伝い!
AIカメラお手軽導入パック




