IoT.kyotoではVieurekaカメラを使ったAIのソリューションを提供しています。
AIカメラでお客様個別の課題解決をサポートする「AIカメラお手軽導入パック」を追加しました!

今回はAIの予測モデルを作成する作業を自動化できるようにしてみました。
全体のアーキテクチャは以下になります。
使用技術
環境デプロイツール:AWS Cloud Development Kit (AWS CDK) v2
CDKの言語:TypeScript
Lambda関数の言語:Python 3.9
機械学習フレームワーク:YOLOv4
モデル学習用、モデル変換用コンテナ保存先:Amazon Elastic Container Registry
AWSアーキテクチャ
AWS側の構成図は以下のようになっています。
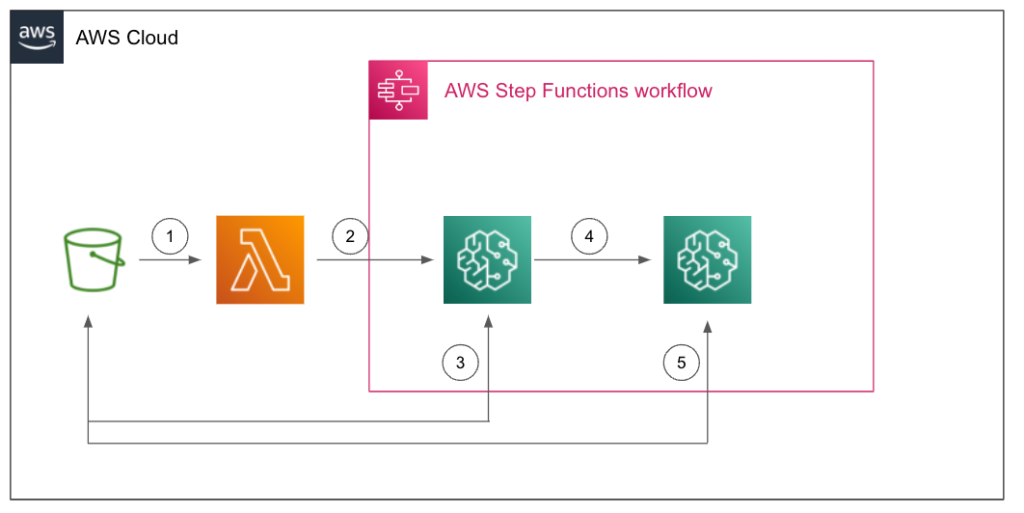
①:S3イベントトリガーでLambdaを起動。アノテーション済みの学習データ(ZIPファイル)をS3にアップロードした後、Lambdaが起動する
②:LambdaがAWS Step Functionsのステートマシンを起動。ステートマシンではまずSageMakerのトレーニングジョブを起動する
③:トレーニングジョブはS3バケットから学習用データを取得し、学習済みモデルファイルをS3バケットに出力する
④:ステートマシンが学習済みモデルファイル変換作業のため、トレーニングジョブを起動する
⑤:トレーニングジョブはS3バケットから学習済みモデルファイルを取得し、変換後のモデルファイルをS3バケットに保存する
S3バケットに学習データをアップロードするだけで、モデルのトレーニング、変換までの一連の流れを自動的に実施するような仕組みになっています。
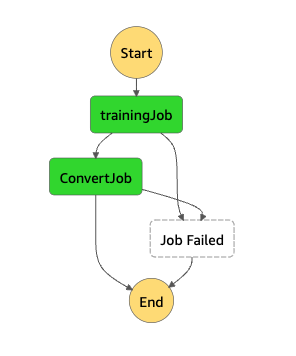
また、実際のAWS Step Functions(以下Step Functionsと記載)のステートマシンは以下のようになります。
CDKソースコード解説
では、実際にCDKのコードを見ていきましょう。
今回はソースコードの重要な部分のみに絞って解説します。
以下がStep Functionsでトレーニングジョブを作成する部分です。
const trainingJob = new tasks.SageMakerCreateTrainingJob(
this,
"trainingJob",
{
trainingJobName: sfn.JsonPath.stringAt(
"$$.Execution.Input['TrainingJobName']"
),
integrationPattern: sfn.IntegrationPattern.RUN_JOB,
algorithmSpecification: {
trainingImage: tasks.DockerImage.fromEcrRepository(
ecr.Repository.fromRepositoryName(
this,
"TrainRepositoryArn",
globalEnv.trainRepository
),
"latest"
),
trainingInputMode: tasks.InputMode.FILE,
},
inputDataConfig: [
{
channelName: "train",
dataSource: {
s3DataSource: {
s3DataType: tasks.S3DataType.S3_PREFIX,
s3Location: tasks.S3Location.fromJsonExpression(
"$$.Execution.Input['BucketPathForTrainData']"
),
s3DataDistributionType:
tasks.S3DataDistributionType.FULLY_REPLICATED,
},
},
},
],
outputDataConfig: {
s3OutputLocation: tasks.S3Location.fromJsonExpression(
"$$.Execution.Input['BucketPathForModelData']"
),
},
resourceConfig: {
instanceCount: 1,
instanceType: new ec2.InstanceType("g4dn.xlarge"),
volumeSize: Size.gibibytes(30),
},
stoppingCondition: {
maxRuntime: Duration.hours(1),
},
hyperparameters: {
data_file: sfn.JsonPath.stringAt(
"$$.Execution.Input['TrainingDataFineName']"
),
},
}
);
trainingJob.addCatch(jobFailed);CDKのSageMakerCreateTrainingJobについての詳細は以下を参照下さい。
class SageMakerCreateTrainingJob (construct)
では、内容について順番に解説していきます。
まず、以下の部分を解説します。
trainingJobName: sfn.JsonPath.stringAt(
"$$.Execution.Input['TrainingJobName']"
)stn.JsonPath.stringAt関数ですが、Step Functionsでパラメータを動的に変更する場合、「”TrainingJobName.$”: “$$.Execution.Input[‘TrainingJobName’]”」のような形で表現する必要があります。詳細は省略しますが、パラメータを動的に変更する場合JSONのキーの末尾に「.$」を付ける必要があります。値部分はJsonPath形式で表現できます。
このような形式に変換する必要がある場合にstn.JsonPath.stringAt関数を使います。
class JsonPath
なお、パラメータを動的に変更する部分の詳細は以下を参照下さい。
InputPath、パラメータ、および ResultSelector
次に「”$$.Execution.Input[‘TrainingJobName’]”」の部分ですが、これはコンテキストオブジェクトと呼ばれるものです。
コンテキストオブジェクトを利用すると、ステートマシンへの入力値をグローバル変数的に参照することができます。今回は2つのトレーニングジョブのタスクがステートマシンへの入力を参照するので、コンテキストオブジェクトから参照するようにしています。
コンテキストオブジェクト
次は「integrationPattern: sfn.IntegrationPattern.RUN_JOB,」の部分を解説します。
Step Functionsにはサービス統合パターンと言う設定があり、サービス同士をどうつなげるのかを制御する事ができます。
具体的にいうと、あるタスクの処理が完了するのを待つのか、HTTPのレスポンスが返った段階で次のタスクに進むのか、等を制御できます。
今回はタスクが直前のタスクに依存しているため、ジョブの完了を待つ(RUN_JOB)を選択しています。
サービス統合パターン
「inputDataConfig」について解説します。
この部分の記述でSageMakerのトレーニングジョブ(実行コンテナ内)に学習データ等を渡すことができます。
具体的に説明しますとS3に存在する特定のファイルをトレーニングジョブ実行コンテナの特定のパスにマウントする事ができる、という形です。
詳細は以下を参照下さい。
Amazon SageMaker がトレーニング情報を提供する方法
その他の記述についてはコードを参照頂ければおおよそのイメージがつくと思いますので解説を省略します。
CDKでStep Functionsを作成する場合のメリット
Step Functionsのステートマシンには必要なロールを設定する必要があるのですが、CDKで実装するとロールへの適切な権限付与が自動的に行われます。
なので、今回のプロジェクトにおいてはStep Functionsステートマシンのロール作成等は特に記述せずにステートマシンを作ることができます。
最後に
今回のユースケースではStep Functionsの利用がとてもマッチしました。トレーニングジョブ2つは合計で30分程度かかる処理なので、Lambda等でフローを実装するのも難しいです。また、今回は実装していませんが、処理の開始、終了をSlack等に通知するなどを実現するとより使いやすいと思います。




